


With Local Reasoning, You Don't Need AGI

DeepSeek R1 starts off 2025 with performant distilled reasoning models
Paper: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Researchers from Deepseek are interested in implemented reinforcement learning based models to allow for reasoning. Previous approaches have not matched the general reasoning performance of OpenAI's o1 series models.

Hmm..What’s the background?
DeepSeek-R1-Zero, trained purely with RL, demonstrates the emergence of powerful reasoning behaviors, such as self-verification, reflection, and the generation of long chains of thought (CoTs). DeepSeek-R1 incorporates cold-start data and a multi-stage training pipeline with two RL and two SFT stages, further improving upon DeepSeek-R1-Zero.
So what is proposed in the research paper?
Here are the main insights:
The research demonstrates that reasoning patterns from larger models can be distilled into smaller models, resulting in better performance than RL on smaller models alone
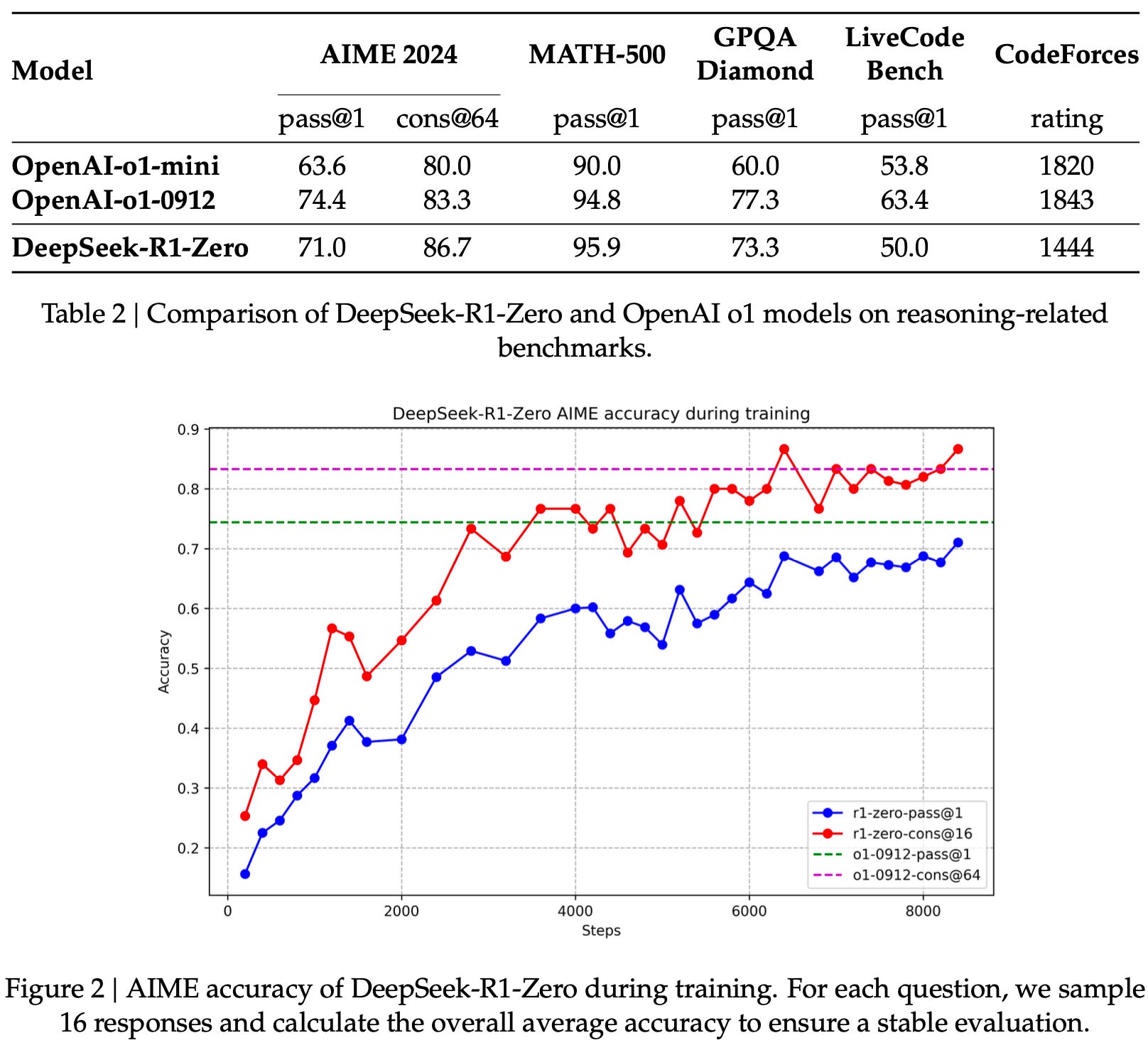
DeepSeek-R1-Zero showed a significant increase in performance on AIME 2024 from 15.6% to 71.0% using a pass@1 score, and 86.7% with majority voting which is comparable to OpenAI-o1-0912
DeepSeek-R1 achieves performance on par with OpenAI-o1-1217 on reasoning tasks
DeepSeek-R1-Zero, DeepSeek-R1, and six dense distilled models are open-sourced for the research community
What’s next?
The researchers plan to enhance DeepSeek-R1's capabilities in function calling, multi-turn conversations, complex role-playing, and JSON output using long CoTs.
DeepSeek R1 starts off 2025 with performant distilled reasoning models
Learned something new? Consider sharing it!