
WebWatcher Wins!

Alibaba model WebWatch processes visual web search with ease!
Paper: WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
Github: https://github.com/Alibaba-NLP/WebAgent
Researchers from Alibaba are interested in web ai gents which offer better and more visually compatible web search.
Hmm..What’s the background?
Existing multimodal deep research agents often rely on rigid, template-driven pipelines that are limited to specific scenarios, lacking the flexible reasoning required for real research challenges. Many current Vision-Language (VL) agents primarily use visual tools, struggling to integrate visual reasoning with deep textual understanding and cross-modal inference, thus failing at high-difficulty tasks that require complex reasoning.
There is a critical gap for agents that not only possess strong reasoning across both textual and visual information but also effectively utilize multiple external tools.

So what is proposed in the research paper?
Here are the main insights:
WebWatcher leverages high-quality synthetic multimodal trajectories for efficient cold start training
Harvesting real-world knowledge via random walks over diverse web sources to build high-difficulty question-answering (QA) examples
Employing a multi-stage filtering process (selector and examiner using GPT-4o) to ensure the quality and clarity of the generated VQA data and reasoning
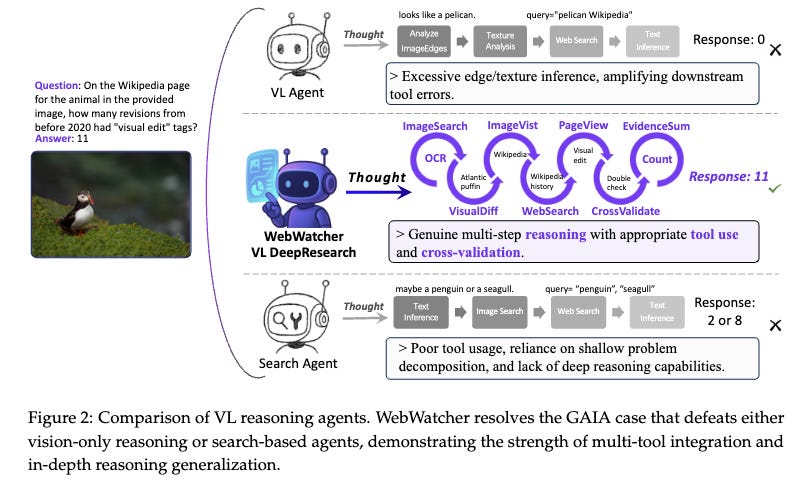
Experimental results demonstrate that WebWatcher significantly outperforms proprietary baselines (e.g., GPT-4o, Gemini 2.5-flash, Claude 3.7) and open-source agents across four challenging VQA benchmarks: Humanity’s Last Exam (HLE-VL), BrowseComp-VL, LiveVQA, and MMSearch
What’s next?
Researchers establish a strong foundation for future multimodal DeepResearch agents capable of solving real-world problems with autonomy, flexibility, and deep reasoning
Alibaba model WebWatch processes visual web search with ease!
Learned something new? Consider sharing it!