
TinyLlama is here! 🪩🦙😎

So essentially,
TinyLlama shows that small models can be mighty! 🦾
Paper: TinyLlama: An Open-Source Small Language Model (8 pages)
Researchers from the Singapore University of Technology and Design are interested in developing more performant models that are smaller in size. They want to put a focus on inference-optimal language models in addition to the current industry focus on training-optimal models.
Hmm..What’s the background?
The industry has a preference for large models trained on large data
The potential of training smaller models with larger datasets remains under-explored

Source: https://lexica.art/prompt/a25dd0a4-a924-41a7-ab68-0cb29bde6e03

Ok, So what is proposed in the research paper?
The main motivation for this work is to explore the behavior of smaller models when trained with a significantly larger number of tokens than what is suggested by current scaling laws
Specifically, the authors train a 1.1B parameter Transformer decoder-only model using approximately 3 trillion tokens.
This is the first attempt to train a model with 1B parameters using such a large amount of data.
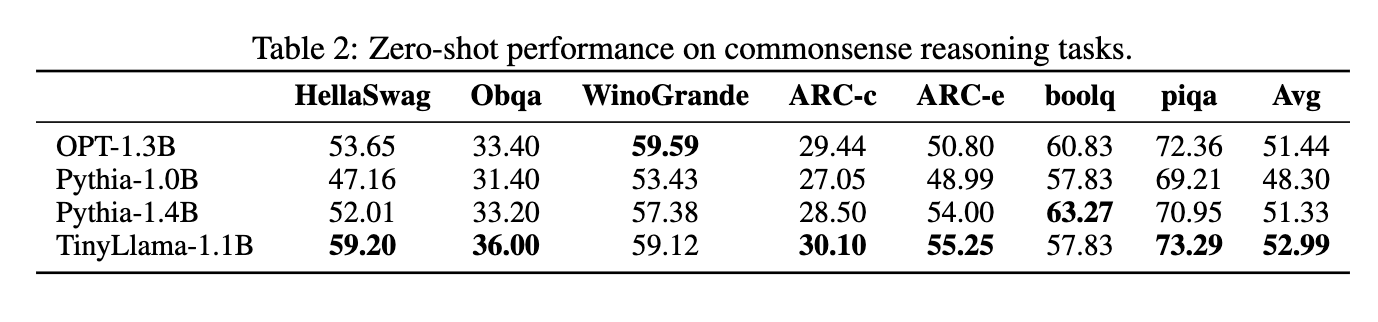
As a result, TinyLlama, shows competitive performance compared to existing open-source language models of similar sizes.
And what’s next?
As the model was trained on a massive dataset of approximately 950 billion tokens, this makes it computationally expensive to train. Also, The model is relatively small and was trained on a mixture of natural language data and code data, which may lead to some bias in the model's performance on certain tasks.
The next steps could include scaling the model to larger sizes, exploring different training data, investigating new training methods, and developing new applications using this model.
So essentially,
TinyLlama shows that small models can be mighty! 🦾