


Time-MoE: Foundation Model
Time-MoE is a better time series prediction foundational model
Paper: Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts (29 Pages)
Github: https://github.com/Time-MoE/Time-MoE
Researchers from Princeton University ,Squirrel Ai Learning and Griffith University are interested in new architecture for time series foundation models that leverages a sparse design with a mixture-of-experts (MoE).
Hmm..What’s the background?
The authors of the sources trained TIME-MoE models on a newly introduced large-scale dataset called Time-300B, which comprises over 300 billion data points spanning nine domains. They scaled TIME-MoE up to 2.4 billion parameters, with 1.1 billion activated, representing the first time a sparsely-activated time series model reached this scale.

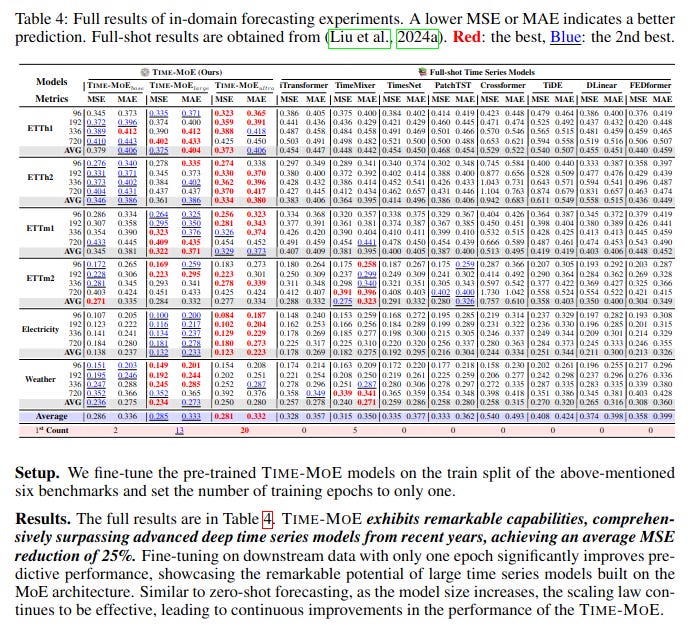
Ok, So what is proposed in the research paper?
The main proposal in the sources is TIME-MoE, a new, scalable and unified architecture for pre-training large time series foundation models for universal forecasting. TIME-MoE is designed to improve forecasting capabilities while reducing computational costs.
It comprises a family of decoder-only transformer models that operate in an autoregressive manner and it supports flexible forecasting horizons and can accommodate varying input context lengths of up to 4096.
What’s next?
Future work could explore even larger models trained on more massive datasets to further improve forecasting accuracy and unlock new capabilities.
So essentially,
Time-MoE is a better time series prediction foundational model
Learned something new? Consider sharing it!