


Reinforcement Learning with Tools

Your AI agent should be reasonably tuned to your tools
Paper: Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
Researchers from Microsoft Research are interested in effective method for enhancing LLMs' reasoning abilities.
Hmm..What’s the background?
Large language models (LLMs) have made significant progress in complex reasoning tasks. Reinforcement learning (RL) is an effective method for enhancing LLMs' reasoning abilities by leveraging outcome-based reward signals, leading to longer, more coherent chains of thought. However, RL-enhanced LLMs still primarily rely on internal knowledge and language modeling.
This reliance limits them for time-sensitive or knowledge-intensive questions where static knowledge may be outdated or incomplete, potentially leading to inaccuracies or hallucinations. Prompting and supervised fine-tuning can teach tool use but are limited by curated data and struggle to adapt to new tasks or recover from failures. Models often misuse tools or revert to brittle behaviors.

So what is proposed in the research paper?
Here are the main insights:
ARTIST (Agentic Reasoning and Tool Integration in Self-Improving Transformers), a unified framework that tightly couples agentic reasoning, reinforcement learning, and tool integration for LLMs
It leverages outcome-based RL (specifically GRPO) to learn robust strategies for tool use and environment interaction without requiring step-level supervision
A composite reward mechanism guides training, including Answer Reward (for correct final answers), Format Reward (for adhering to the prompt template structure), and Tool Execution Reward (for successful tool calls). For math tasks, there is also a specific format reward structure and a tool execution reward based on successful Python code executions. For function calling, rewards include State Reward (for tracking/updating state variables) and Function Reward (for issuing the correct sequence of function calls)
ARTIST consistently outperforms state-of-the-art baselines on complex mathematical reasoning and multi-turn function calling benchmarks
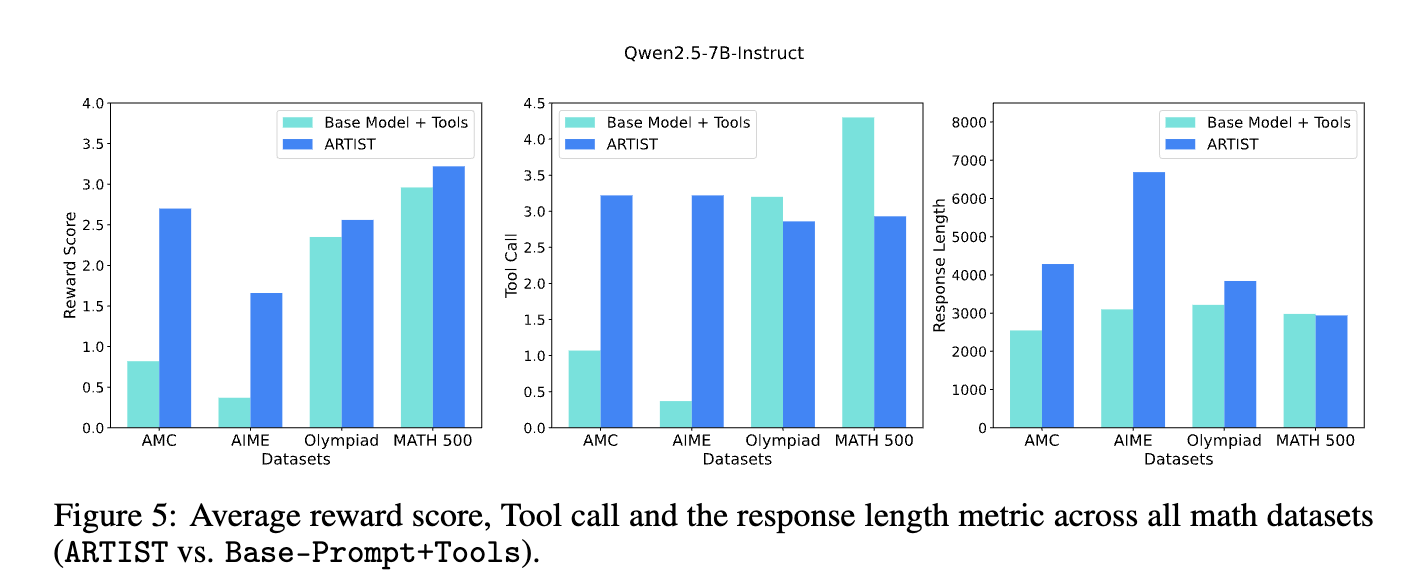
What’s next?
We need to explore scaling ARTIST to even more diverse domains. As well as addressing safety and reliability in open-ended environments and incorporate techniques used by models like DeepSeek-R1 (large teacher models or additional supervised alignment) could further enhance the models.
Your AI agent should be reasonably tuned to your tools
Learned something new? Consider sharing it!