


New Paradigm with 1 bit LLMs! 🚀🤖🚀

So essentially,
1 bit LLMs are both high-performant and cost-effective!
Paper: The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits [8 Pages]
Researchers from thegenerality are interested in training LLMs more cost-effectively while maintaining the performance of models. They focus on developing foundational models with are aligned with sustainable engineering for humanity.
Hmm..What’s the background?
Language models demonstrate remarkable performance in a wide range of natural language processing tasks, but their increasing size has posed challenges for deployment and raised concerns about their environmental and economic impact due to high energy consumption. One approach to address these challenges is to use post-training quantization to create low-bit models for inference. However, post-training quantization is sub-optimal, even though it is widely used in industry LLMs. Recent work on 1-bit model architectures, such as BitNet, has presented a promising direction for reducing the cost of LLMs while maintaining their performance.
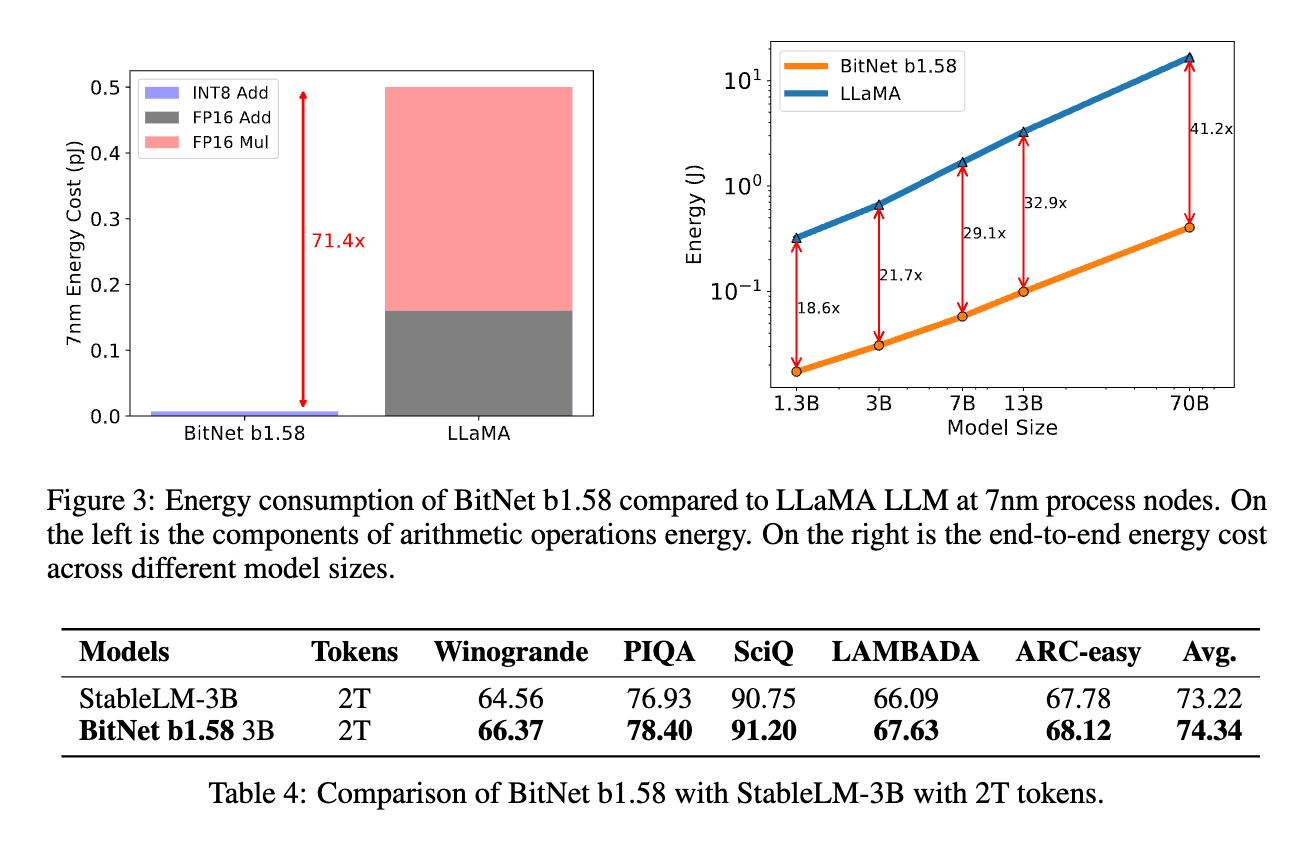
BitNet b1.58 retains all the benefits of the original 1-bit BitNet, including its new computation paradigm, which requires almost no multiplication operations for matrix multiplication and can be highly optimized.

Ok, So what is proposed in the research paper?
The proposed research introduces a significant 1-bit LLM variant called BitNet b1.58, where every parameter is ternary, taking on values of {-1, 0, 1}.
BitNet b1.58 has the same energy consumption as the original 1-bit BitNet and is much more efficient in terms of memory consumption, throughput, and latency compared to FP16 LLM baselines. BitNet b1.58 also has stronger modeling capabilities due to its explicit support for feature filtering and can match full precision (FP16) baselines in terms of perplexity and end-task performance, starting from a 3B size.
And what’s next?
The researchers discuss potential future improvements and integrations that can enhance the utilization of these models:
1-bit Mixture-of-Experts (MoE) LLMs: 1.58-bit LLMs could address challenges of high memory consumption and inter-chip communication overhead.
Native Support of Long Sequence in LLMs: They could reduce memory consumption introduced by the KV caches which is a major challenge for long sequence inference.
LLMs on Edge and Mobile: These models enable capabilities of edge and mobile devices, and new applications of LLMs.
New Hardware for 1-bit LLMs: This calls for actions to design new hardware and system specifically optimized for 1-bit LLMs, given the new computation paradigm enabled.
So essentially,
1 bit LLMs are both high-performant and cost-effective!