
MM-IQ Test for AI

AI has low Visual IQ
Paper: MM-IQ: Benchmarking Human-Like Abstraction and Reasoning in Multimodal Models
Researchers from Tencent Hunyuan are interested in evaluating the abstract reasoning capabilities of multimodal models (LMMs).

Hmm..What’s the background?
Current benchmarks often assess task-specific skills like OCR and object localization, but MM-IQ aims to isolate core cognitive competencies by focusing on abstract visual reasoning (AVR), which requires identifying underlying rules and generalizing them to new situations.
The benchmark includes 2,710 carefully chosen problems spanning eight distinct reasoning paradigms, such as logical operations, mathematics, and spatial relationships, all while minimizing linguistic and domain-specific biases.
So what is proposed in the research paper?
Here are the main insights:
Larger models perform better than smaller ones, and open-source models can achieve comparable results to proprietary ones
A detailed failure analysis of the models revealed that a significant portion of errors stem from incorrect reasoning due to reliance on simpler rules rather than extracting higher-level abstract paradigms
The MM-IQ benchmark has shown that current state-of-the-art LMMs perform only slightly better than random chance (around 27% accuracy), which is far below human-level performance (51.27%), highlighting a significant gap in their abstract reasoning abilities.
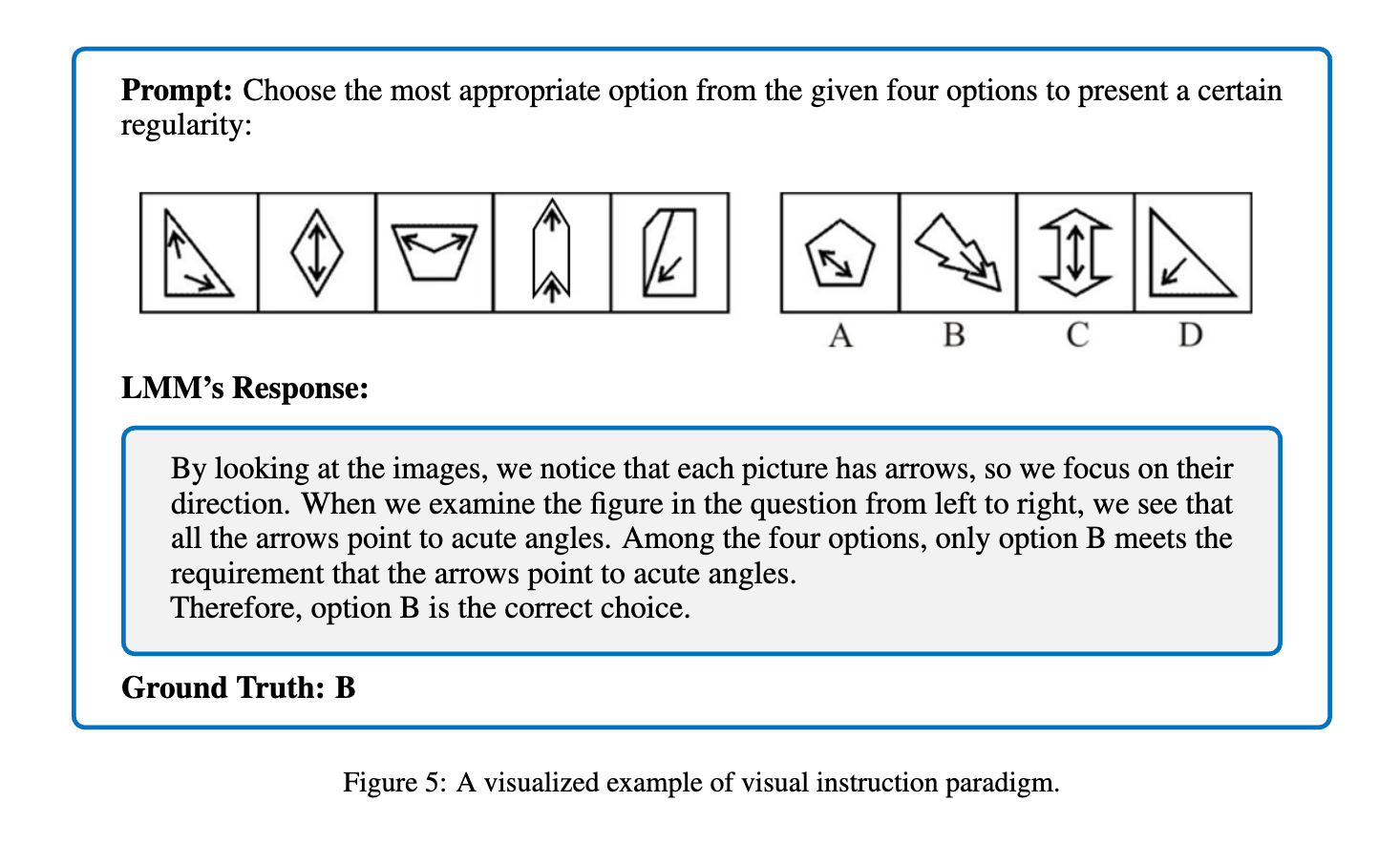
What’s next?
Future work will likely focus on several key areas to improve LMM performance on abstract visual reasoning tasks like Structured reasoning, Abstract pattern recognition and Visual Understanding
AI has low Visual IQ
Learned something new? Consider sharing it!