
LongLLaVa overflowing!
So essentially,
LongLLaVA can process upto 1000 images (140K tokens) at a time!
Paper: LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture (19 Pages)
Github: https://github.com/FreedomIntelligence/LongLLaVA
Researchers from Shenzhen, China are interested in processing up to a 1000 images at a time with LLaVA architecture.
Hmm..What’s the background?
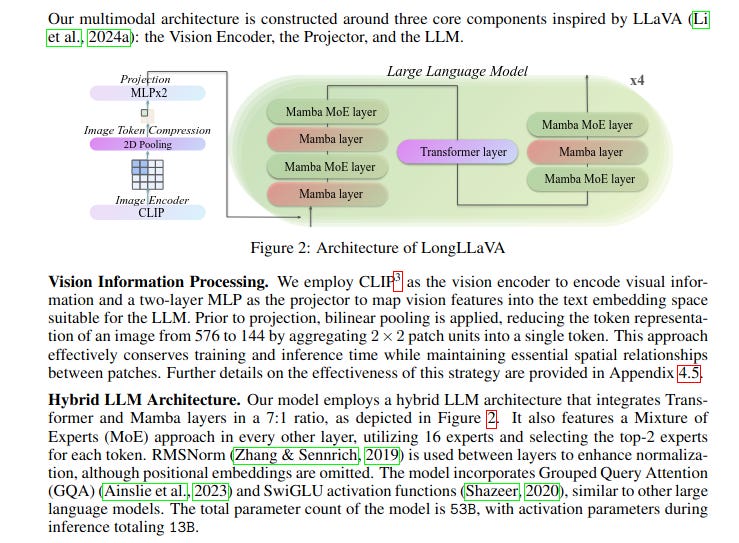
The research on LongLLaVA (Long-Context Large Language and Vision Assistant) is rooted in the pursuit of enhancing Multi-modal Large Language Models (MLLMs) to effectively handle long-context scenarios, particularly those involving multiple images.
While MLLMs have shown great promise in various applications, their performance degrades and computational costs soar when dealing with multiple images.

Ok, So what is proposed in the research paper?
This research proposes a hybrid architecture combining Transformer and Mamba layers to address the limitations of existing architectures. The rationale behind this approach is:
Balancing Effectiveness and Efficiency: The Mamba-Transformer hybrid architecture aims to strike a balance between effectiveness in ICL tasks and efficiency in handling long sequences
While Transformer models excel at ICL but suffer from quadratic computational complexity, Mamba models boast linear complexity but lack strong ICL capabilities. The hybrid approach aims to leverage the strengths of both
Improved Efficiency: The linear computational complexity of Mamba contributes to the hybrid architecture's efficiency. Jamba, a popular hybrid model, demonstrates significantly higher throughput and reduced memory requirements compared to pure Transformer models like LLaMA2-7B and Mixtral 8×7B
What’s next?
The researchers remark that these could directions for future work to further enhance LongLLaVA's capacity for handling a larger number of images, the authors propose extending the training sequence length to 140,000 tokens - the maximum limit for single-card inference with the current model. Additionally, The authors suggest that incorporating more single-image data during the Multi-image Instruction-tuning stage could potentially address this performance gap.
So essentially,
LongLLaVA can process upto 1000 images (140K tokens) at a time!
Learned something new? Consider sharing with your friends!