


LLMLingua: Prompt Compression makes LLM Inference Supercharged 🚀

So essentially,
"LLMLingua by Microsoft allows for compressed prompts which are 20x more token efficient! "
Paper: LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
Researchers from Microsoft Corporation are interested in compressing a long prompt into a shorter one without any gradient flow through the LLMs to support applications based on a range of LLMs.
From previous research, we know that in practical applications, crafting suitable prompts is crucial and often involves techniques such as chain-of-thought, in-context learning, and retrieving related documents or historical conversations. These require verbose and specific prompts. Through this paper, the researchers attempt to reduce the length of original prompts while preserving essential information. These approaches are grounded in the concept that natural language is inherently redundant (Shannon, 1951) and thus can be compressed.

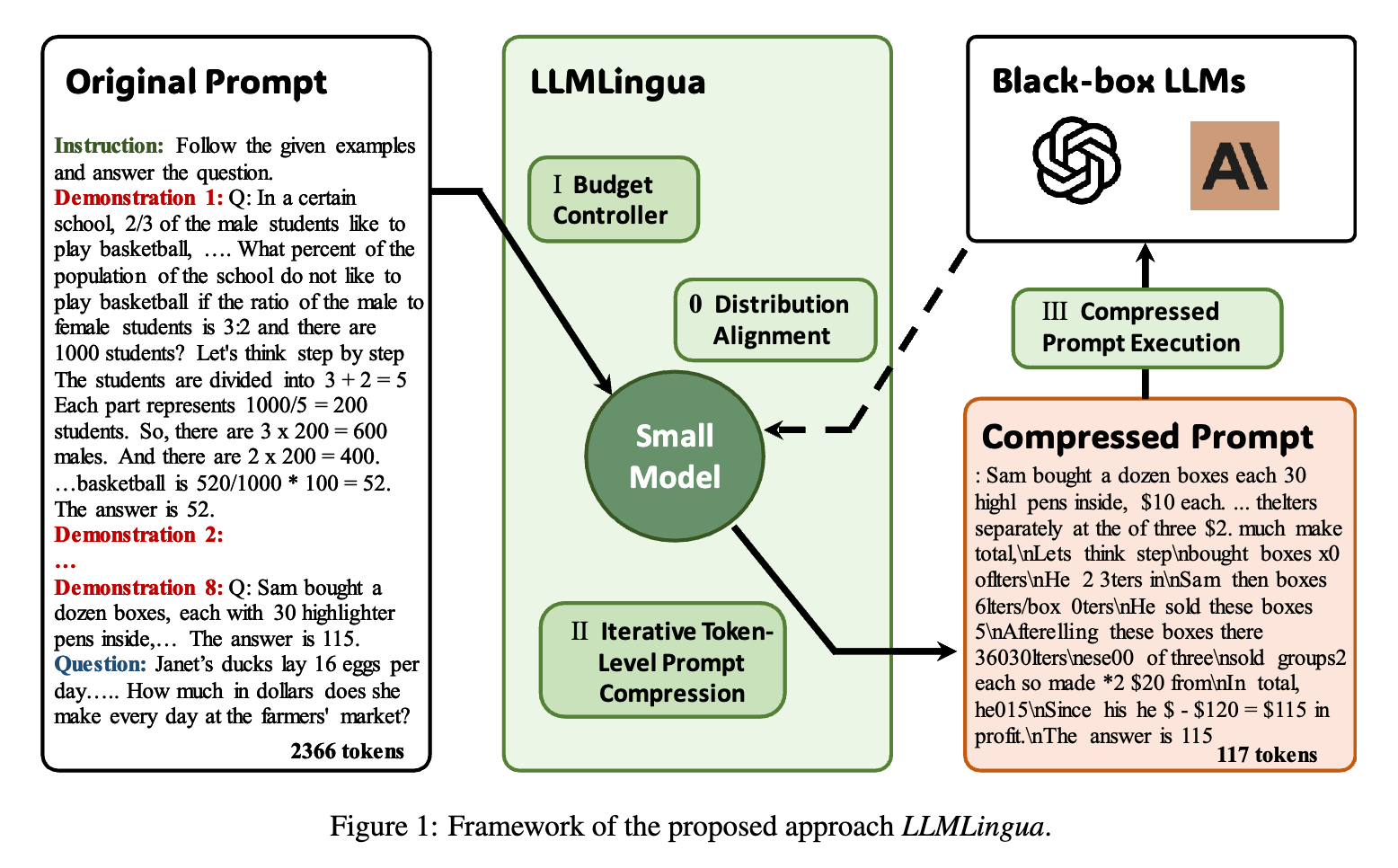
From the paper, the researchers propose the following methodology:
Firstly, a budget controller to dynamically allocate different compression ratios to various components in original prompts such as the instruction, demonstrations, and questions while maintaining semantic integrity under high
compression ratios.
They further introduce a token-level iterative algorithm for fine-grained compression.
Compared with Selective Context, these strategies can better preserve the key information within the prompt through the conditional dependencies between tokens.
Finally, the researchers pose the challenge of distribution discrepancy between
the target LLM and the small language model used for prompt compression, and further, propose an instruction tuning-based method to align the distribution of both language models.
For evaluation, these were some specifications:
Dataset: Arxiv-March23, consists of 500 academic papers from the arXiv preprint repository collected in March 2023.
Testset: Data items from the Arxiv-March23 dataset. To reduce the length of some articles, the researchers truncated each section to 10,000 characters and then concatenated these sections to form the original prompt.
Model: GPT-3.5- Turbo for generating summaries.
Evaluation metrics: ROUGE (Recall-Oriented Understudy for Gisting Evaluation) and METEOR (Metric for Evaluation of Translation with Explicit ORdering) to evaluate the quality of the generated summaries.
The paper discusses the importance of chain-of-thought (CoT) models for natural language processing tasks and provides examples including text generation, question-answering, and dialogue systems. LLMLingua authors reported that their approach showed significant improvement in summary quality compared to the baseline approach, as measured by ROUGE and METEOR scores. Their approach generated more informative and coherent summaries than the baseline approach with 20x compression with minimal performance loss.
Their future work would involve investigating the use of CoT models for improving the performance of other natural language processing tasks, such as machine translation and sentiment analysis as well as examining the use of CoT models in multimodal learning, where they can be used to generate summaries of scientific papers in combination with other modalities, such as images or videos.
So essentially,
"LLMLingua by Microsoft allows for compressed prompts which are 20x more token efficient! "