
LLM⚡CPU wins continued ...

So essentially,
Intel releases XFasterTransformer to optimize LLMs for CPU 🚀
Paper:
Inference Performance Optimization for Large Language Models on CPUs
(5 Pages)
Github:
https://github.com/intel/xFasterTransformer
Researchers from Intel want to develop practical solutions for deployment of Large Language Models which are currently restrictive due to high costs and hardware resource limitations.
Hmm..What’s the background?
Large language models (LLMs), based on the Transformer architecture, have garnered significant attention and demonstrated exceptional performance across various tasks. To mitigate the financial burden and alleviate constraints imposed by hardware resources, optimizing inference performance is necessary.
To address this challenge, the research focuses on optimizing the inference performance of LLMs on CPUs, providing a cost-effective alternative to resource-intensive GPU deployments. This offers several advantages, including freedom from VRAM size restrictions, prevention of KV cache overflow, and support for processing extremely long contexts.

Ok, So what is proposed in the research paper?
This solution includes several key contributions:
The researchers propose new LLM optimization solutions specifically designed for CPUs, such as SlimAttention. They perform individual optimizations for LLM operations and layers across widely used models like Qwen, Llama, ChatGLM, Baichuan, and the Opt series
An effective method for reducing the KV cache size while maintaining precision is implemented, ensuring efficient memory use without significantly compromising output quality
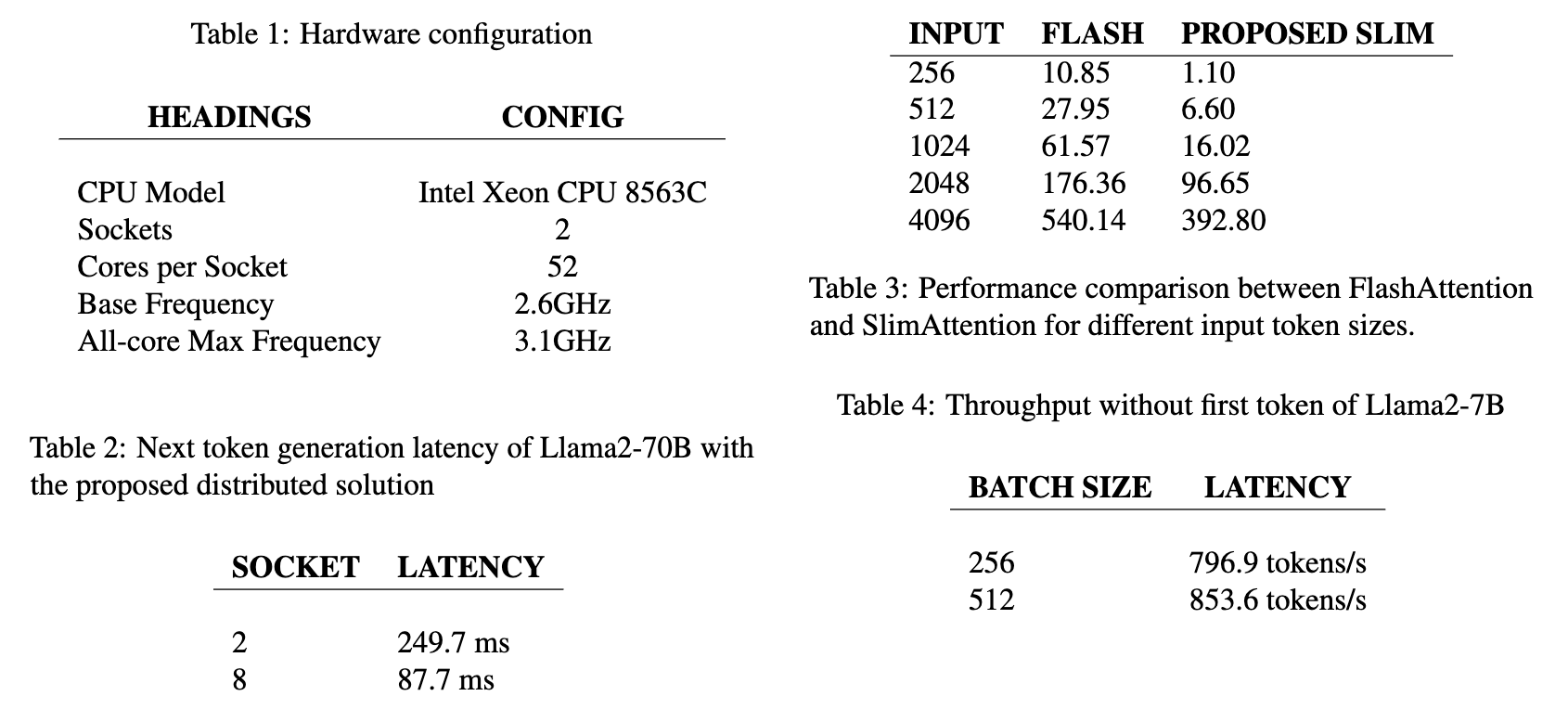
A distributed inference optimization solution for LLMs on CPUs is designed and implemented using the oneAPI Collective Communications Library (oneCCL). This facilitates scalability and efficient low-latency inference.
The researchers demonstrate the effectiveness of their solution through experiments on the Intel Xeon CPU 8563C. Their distributed inference solution achieves a 2.85X performance gain for Llama2-70B on 8 sockets compared to 2 sockets. The SlimAttention approach exhibits superior performance to FlashAttention for various input token sizes on a single socket.
What’s next?
For future work, the authors plan to:
Expand their research to encompass a wider range of CPUs, particularly those with resource constraints
Focus on improving performance for larger batch sizes
Explore effective deployment serving solutions
Adapt their solution to support emerging models, such as mixture of experts (MoE) models
So essentially,
Intel releases XFasterTransformer to optimize LLMs for CPU 🚀