
LlamaDuo: Seamless Migration from Service LLMs to Small-Scale Local LLMs
So essentially,
Small Local LLMs are better than Cloud Service LLMs
Paper: LlamaDuo: LLMOps Pipeline for Seamless Migration from Service LLMs to Small-Scale Local LLMs (28 Pages)
Github: https://github.com/deep-diver/llamaduo
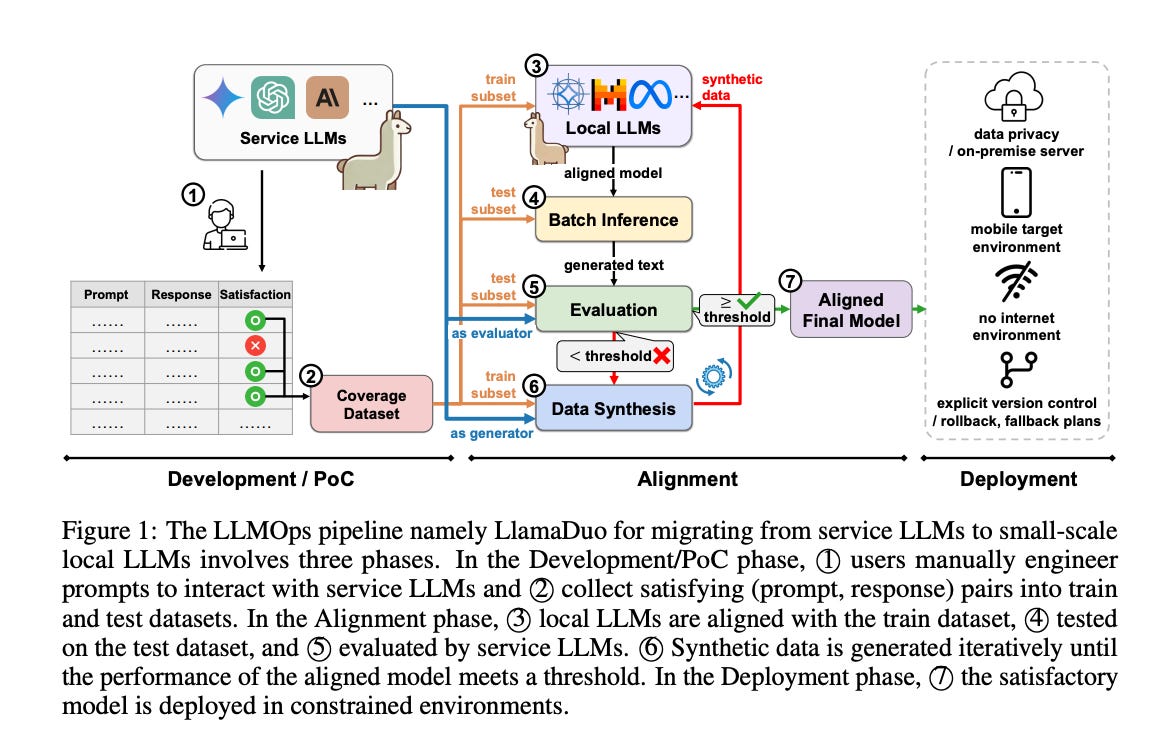
Researchers from multiple leading research institutes propose LlamaDuo, an LLMOps pipeline designed for migrating knowledge and abilities from service-oriented LLMs to smaller, locally manageable LLMs. This approach aims to ensure service continuity, enhance privacy, and enable AI deployment in constrained environments.
Hmm..What’s the background?
Reliance on cloud-based LLMs can lead to service disruptions and inconsistencies due to updates on the provider's end. Additionally, Transmitting sensitive information to external providers for LLM utilization heightens data privacy risks.
LlamaDuo leverages the power of service LLMs to generate high-quality synthetic data based on a smaller, task-specific "coverage dataset" provided by the user. This synthetic data is then used to fine-tune open-source, smaller LLMs, improving their performance on specific downstream tasks.

Ok, So what is proposed in the research paper?
Here's a breakdown of how LlamaDuo works:
Coverage Dataset Creation: Users compile a task-specific dataset of prompts and desired responses, referred to as the "coverage dataset"
Initial Fine-tuning: The chosen smaller LLM ("local LLM") undergoes initial fine-tuning using the training subset of the coverage dataset
Batch Inference & Evaluation: The fine-tuned local LLM generates multiple responses for prompts sampled from the test subset of the coverage dataset
Performance Evaluation: Metrics such as mean score and coverage percentage (based on a predefined quality threshold) are calculated from the service LLMs' evaluations
Iterative Refinement with Synthetic Data: If the local LLM's performance falls short, service LLMs generate additional synthetic data
Deployment: Once the local LLM achieves satisfactory performance, it's ready for deployment in environments with resource constraints or offline requirements
What’s next?
The researchers remark that these could directions for future work:
Generalization Across Diverse LLMs
Expanding Task Scope
Evaluating Long-Term Cost-Effectiveness
So essentially,
Small Local LLMs are better than Cloud Service LLMs
Learned something new? Consider sharing with your friends!