


Intro to VLMs

So essentially,
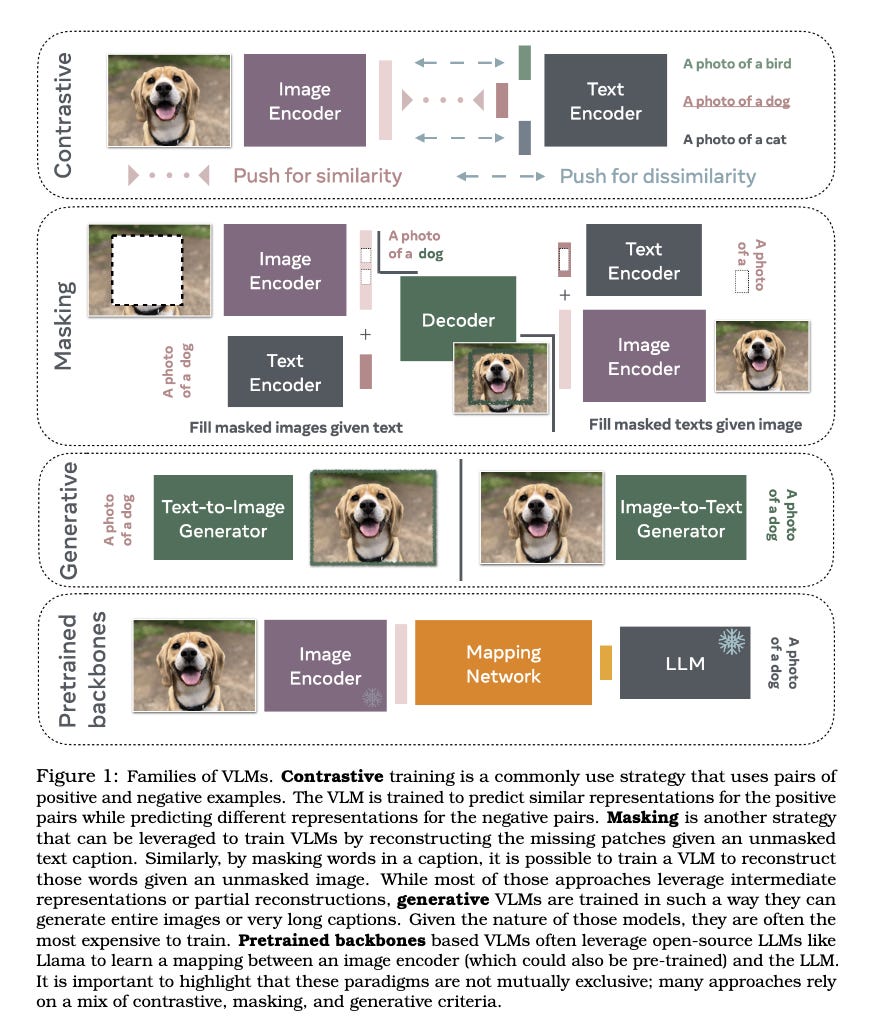
Visual Language Modeling have 4 main strategies for models!
Paper: An Introduction to Vision-Language Modeling (76 Pages)
Researchers from multiple organizations such as Meta, Université de Montréal, McGill University, U Toronto, CMU, MIT, NYU, UCBerkeley, University of Maryland, King Abdullah University of Science and Technology as well as CIFAR AI are interested in Vision-Language Modeling. This paper aims to provide an introduction to Vision Language Models (VLMs) for students or researchers entering the field.

Hmm..What’s the background?
Vision Language Models (VLMs) aim to bridge the gap between computer vision and natural language processing, enabling machines to understand and interpret visual and textual information in a unified manner. There are 4 main methods for Visual Language Models: Contrastive methods (like CLIP), Masking strategies (like FLAVA, MaskVLM), Generative approaches, and models leveraging pretrained backbones (like LLMs, Flamingo, MiniGPT)
Ok, So what is proposed in the research paper?
The paper introduces several technical innovations and describes related technical parameters:
Contrastive models excel at associating text with visual concepts, making them suitable for tasks like image retrieval and grounding.
Requires extensive datasets and resources for training
Masking strategies, involve reconstructing masked image patches or text
These are not generative models
Generative VLMs, capable of generating images or captions
Computationally expensive to train
Pre-trained backbone-based VLMs leverage existing models (like LLMs) by learning mappings between visual and textual representations.
These have gained popularity due to reduced computational needs compared to training from scratch.
Benchmarks like Wino ground, ARO, and PUG are designed to evaluate VLM reasoning capabilities, particularly in handling complex relationships and spatial understanding. However, many benchmarks suffer from limitations such as language bias, emphasizing the need for careful benchmark design.
What’s next?
The authors acknowledge several potential avenues of evolution for these models involving the following:
Improving Data for Training: There is a need for more video caption pairs that describe actions and motions rather than solely scene content. The current lack of this type of data limits a video model's ability to learn temporal understanding.
Enhancing Temporal Understanding in Videos: Existing video-language datasets primarily focus on describing scenes rather than actions or motion, causing video models to function similarly to image models.
Developing More Efficient Training for Videos: Processing videos requires significantly more computational resources than images, making efficient training protocols crucial. One potential area of improvement is exploring the use of masking techniques, which have proven effective in image-based VLMs. By selectively masking out portions of the video or caption, the model can be trained to predict the missing information, encouraging a deeper understanding of the temporal context.
Creating New Benchmarks for Video VLMs: Current benchmarks for video VLMs primarily evaluate their ability to describe scenes, neglecting their capacity to reason about temporal aspects. There is a need for more comprehensive benchmarks that can assess the reasoning capabilities of video VLMs.
So essentially,
Visual Language Modeling have 4 main strategies for models!