
Hymba: Hybrid-head by NVIDIA
Hymba architecture is optimal for Small Language Models
Paper: Building Trust: Foundations of Security, Safety and Transparency in AI(27 Pages)
Github: https://github.com/NVlabs/hymba
Researchers from NVIDIA are interested in better and more efficient architecture. Transformers, the dominant architecture for language models, excel in performance and long-term recall but suffer from quadratic computational cost and high memory demands. Conversely, state space models (SSMs) like Mamba offer constant complexity and efficient hardware optimization but struggle with memory recall tasks, impacting their performance on general benchmarks. Hymba by NVIDIA is posed to be an answer to these woes.
Hmm..What’s the background?
Hymba addresses these limitations with a hybrid-head parallel architecture integrating transformer attention and SSMs for enhanced efficiency. Attention heads offer high-resolution recall, while SSM heads enable efficient context summarization.

So what is proposed in the research paper?
In the research paper Hymba incorporates several key innovations:
Learnable meta tokens, prepended to prompts, store critical information and alleviate the "forced-to-attend" burden of attention mechanisms
Cross-layer key-value (KV) sharing and partial sliding window attention optimize the model, resulting in a compact cache size
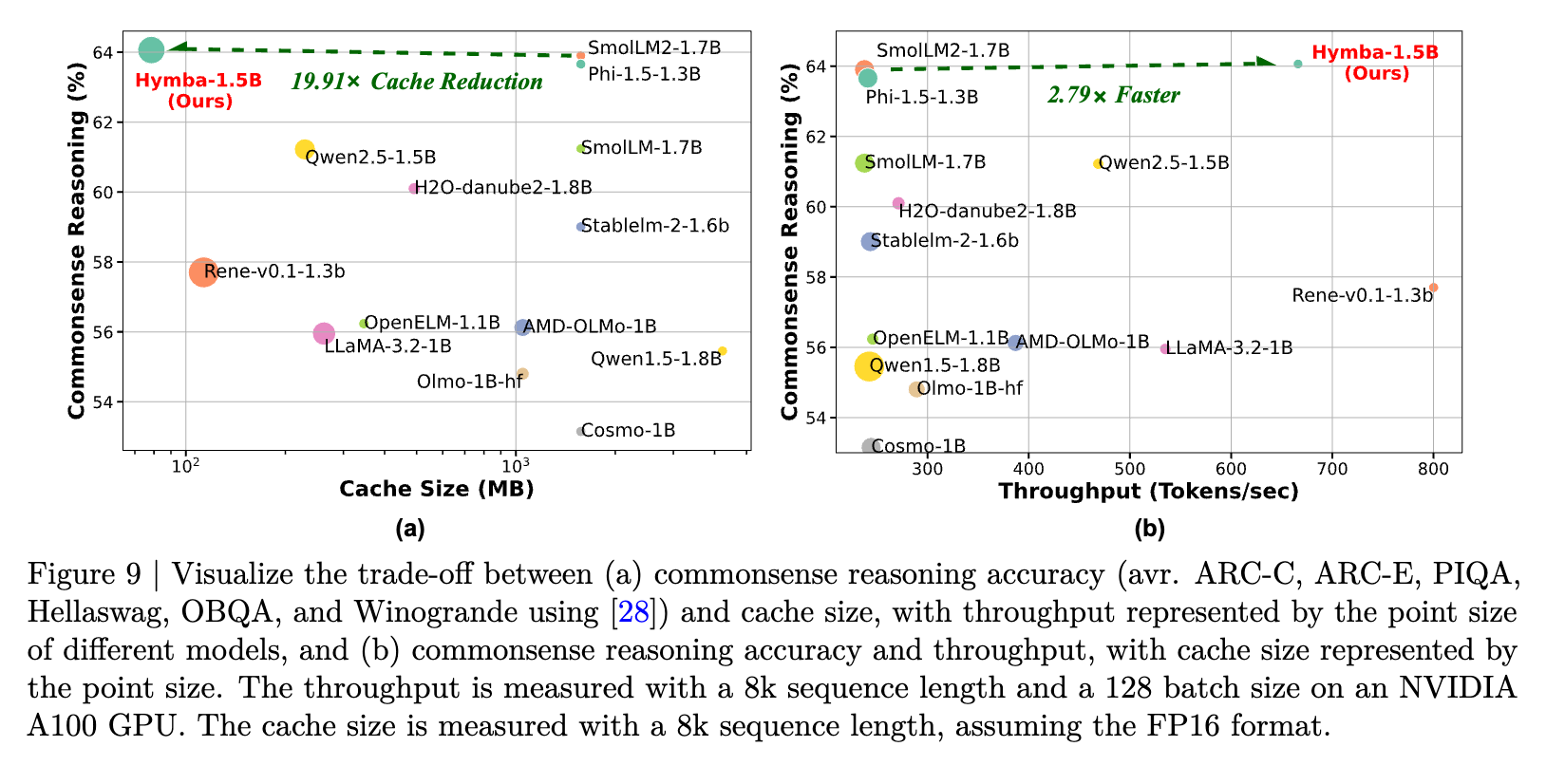
Comprehensive evaluations reveal that Hymba sets a new state-of-the-art benchmark across various tasks while achieving greater efficiency compared to transformers and previous hybrid models. Hymba-1.5B-Base surpasses all sub-2B public models and outperforms Llama-3.2-3B with 1.32% higher average accuracy, 11.67x cache size reduction, and 3.49x throughput.
Instruction-tuned Hymba-1.5B-Instruct achieves best-in-class performance on GSM8K, GPQA, and the Berkeley function-calling leaderboard, surpassing Llama-3.2-1B.
What’s next?
Hymba's hybrid-head architecture effectively combines the strengths of attention and SSM mechanisms, achieving state-of-the-art performance and efficiency in small language models. The introduction of meta tokens, KV cache optimization, and successful instruction-tuning further solidifies Hymba's position as a promising direction for future research in efficient language models!
Hymba architecture is optimal for Small Language Models
Learned something new? Consider sharing it!