
How can compression help with Retrieval Augmented LMs?

So essentially,
"Using compressed summaries to provide extended context provides better RAG!"
Paper: RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation
Researchers from the University of Texas at Austin and the University of Washington are interested in figuring out strategies to reduce computational costs needed in the retrieval of relevant information for language models.
From previous research, we know that Retrieval-augmented language models (RALMs) show impressive performance on knowledge-intensive tasks but create a burden with the computation costs when we have large-scale data.
The main ideas from the paper involve using abstractive (generating summaries by synthesizing information from multiple documents) and extractive (selecting useful sentences from retrieved documents) compression to evaluate language modeling and open-domain question-answering tasks.

In the paper, they describe the following as their methodology:
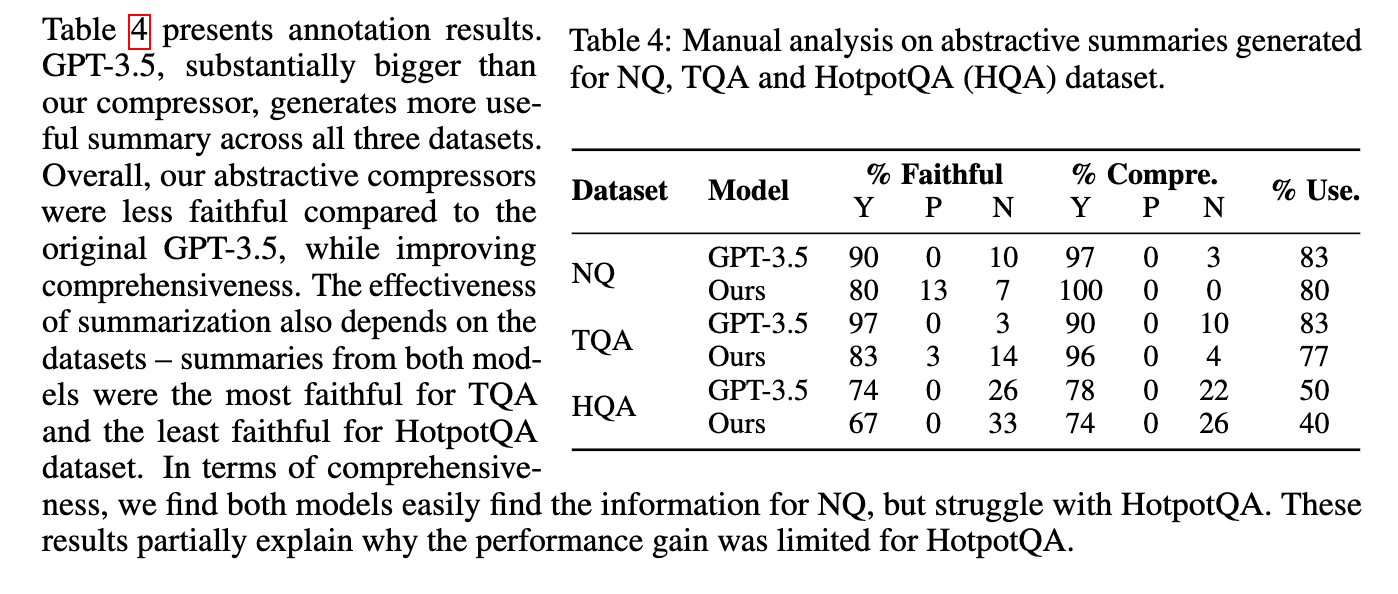
The researchers used a manual analysis approach to label each summary with one of three labels: Not Faithful, Comprehensive, or Faithful and Not Comprehensive. The Faithful label indicates that the summary does not accurately convey the main idea of the passage, while the Comprehensive label indicates that the summary provides a complete and accurate summary of the passage
This allows for a more detailed understanding of the quality of the summaries and provides a basis for comparing the performance of different models.
The researchers evaluated the summaries using a dataset of 12 examples, with each example consisting of a query, passages, and a corresponding summary
The Not Faithful label was given to 41.40% of the summaries, indicating that they do not accurately convey the main idea of the passage.
The Comprehensive label was given to 35.20% of the summaries, indicating that they provide a complete and accurate summary of the passage.
The Faithful and Not Comprehensive label was given to 21.40% of the summaries, highlighting the importance of both accuracy and completeness.
Their future work would involve improving the accuracy of the summaries by developing different techniques for generating summaries. There are opportunities to explore other evaluation methods to assess the quality of the summaries, such as automated metrics or human evaluations. There are also ways to investigate the use of different types of data, such as multi-modal data or data from different domains, to improve the performance of the summarization models as well as examine the use of summarization in different languages or cultures, and explore ways to improve the accuracy of summaries in these contexts.
So essentially,
"Using compressed summaries to provide extended context provides better RAG!"