
GPU gang better watch out!
L-Mul simply uses addition multiple times (instead of multiplication) to allow for energy efficient LLMs
Paper: Addition is All You Need for Energy-efficient Language Models (13 Pages)
Researchers from BitEnergy AI are interested in improving the energy efficiency of large language models.
Hmm..What’s the background?
Large neural networks, especially Large Language Models (LLMs), require significant computational resources and consume a substantial amount of energy, primarily due to the numerous floating-point multiplications involved in tensor computations. This energy consumption poses a significant challenge for the development and deployment of AI systems. L-Mul is proposed as an energy-efficient alternative to traditional floating-point multiplication, aiming to reduce energy consumption and inference speed for large-scale AI models.

Ok, So what is proposed in the research paper?
The paper presents:
Replacing floating-point multiplications with integer additions using L-Mul can significantly reduce energy consumption, potentially by up to 95% for element-wise tensor multiplications and 80% for dot products
Despite its lower computational cost, L-Mul achieves comparable or even higher precision than 8-bit floating-point multiplications, as demonstrated through theoretical analysis and evaluations on various language and vision tasks
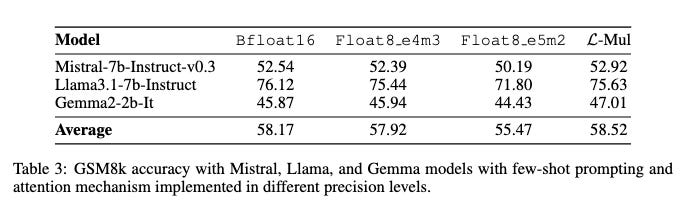
Experiments show that directly applying L-Mul to the attention mechanism in transformer-based LLMs results in almost no performance loss. Replacing all floating-point multiplications with L-Mul in a transformer model can achieve equivalent precision as using float8 e4m3 for accumulation.
What’s next?
The future development of L-Mul will focus on:
Hardware Implementation: Implement the L-Mul and L-Matmul kernel algorithms at the hardware level for optimal performance
API Development: Develop programming APIs for high-level model design
L-Mul Native AI Models: Train textual, symbolic, and multi-modal generative AI models specifically optimized for deployment on L-Mul native hardware
So essentially,
L-Mul simply uses addition multiple times (instead of multiplication) to allow for energy efficient LLMs
Learned something new? Consider sharing it!