
Google Releases Conversational Diagnostic AI!🧑⚕️🤖

So essentially,
Google models can simulate physician-patient dialogue well!
Paper: Towards Conversational Diagnostic AI (46 Pages)
Researchers from Google Research and Google DeepMind are interested in facilitating better physician-patient dialogue for accurate diagnosis and effective management however approximating clinicians’ expertise is an outstanding grand challenge.
Hmm..What’s the background?
Researchers believe that LLMs have the potential to improve accessibility, consistency, and quality of care in healthcare. However, there are significant challenges to overcome before LLMs can be used in clinical practice, such as the need for large amounts of training data and the development of methods for evaluating LLMs' performance in a clinical setting. They are interested in introducing LLMs in assistive contexts.

Ok, So what is proposed in the research paper?
The research introduces AMIE (Articulate Medical Intelligence Explorer), a Large Language Model (LLM) based AI system optimized for diagnostic dialogue. AMIE uses a novel self-play-based simulated environment with automated feedback mechanisms for scaling learning across diverse disease conditions, specialties, and contexts.
AMIE was developed using a self-play-based simulated environment that allowed it to learn from its mistakes and improve its diagnostic accuracy over time. The simulated environment was created by three LLM agents: a patient agent, a doctor agent, and a moderator.
AMIE was trained to predict the next conversational turn in a patient-doctor dialogue, either as the patient or the doctor.
During the inference stage, AMIE uses a chain-of-thought strategy to progressively refine its response conditioned on the current conversation to arrive at an accurate and grounded reply.
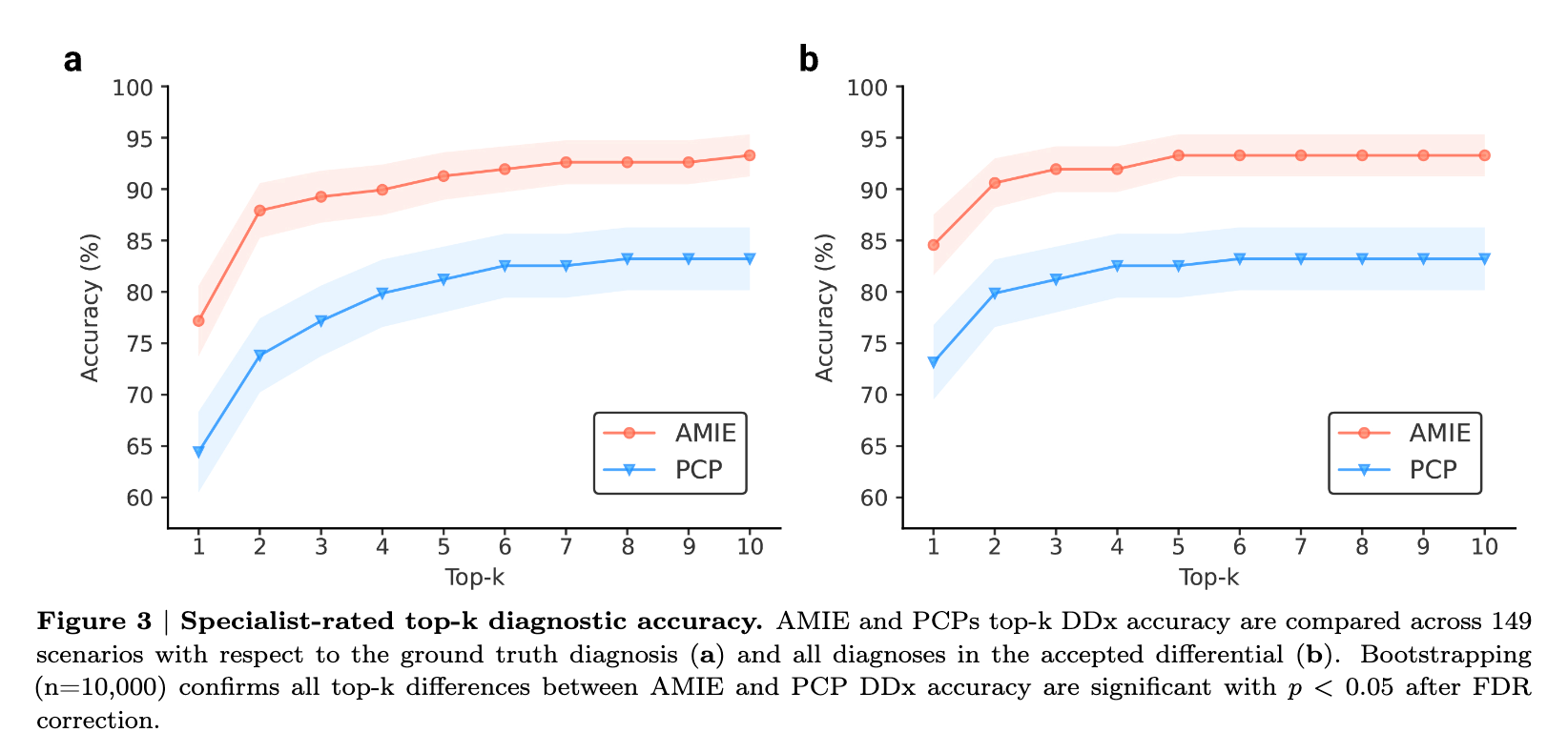
AMIE was able to elicit relevant information from patients and formulate a complete differential diagnosis more accurately than PCPs, even when both were provided with the same acquired information.
AMIE demonstrated superior performance on 28 out of 32 axes of evaluation, as rated by specialist physicians, and 24 out of 26 axes, as rated by patient actors.
And what’s next?
The researchers discuss several unresolved challenges. The study was conducted with a limited sample size of 149 patients, which may not be representative of the general population. Also, The study was conducted in a simulated environment, which may not reflect the real-world clinical setting.
The study focused on AMIE's ability to perform diagnostic dialogue, but the authors suggest that it could be used for a variety of other tasks in healthcare.
So essentially,
Google models can simulate physician-patient dialogue well!