
Going CLEAR 👓
LLMs can CLEAR and forget their fine tuned lessons
Paper: CLEAR: Character Unlearning in Textual and Visual Modalities (20 Pages)
Github: https://github.com/somvy/multimodal_unlearning
Researchers from AIRI, MIPT, Skoltech, Sber, University of Sharjah and HSE University are interested in development of LLMs which can forget i.e. selectively unlearn information.
Hmm..What’s the background?
Large Language Models (LLMs) and Multimodal LLMs (MLLMs) are trained on massive datasets that may contain private, unethical, or undesirable information. Machine Unlearning (MU) methods aim to remove this unwanted data from trained models without the need for costly retraining from scratch.
While MU has progressed in textual and visual modalities, MMU, which deals with unlearning in multimodal models, is relatively unexplored, partly due to the lack of a suitable benchmark. This is partly because existing MU benchmarks focus on single modalities, making them unsuitable for MMU evaluation.

Ok, So what is proposed in the research paper?
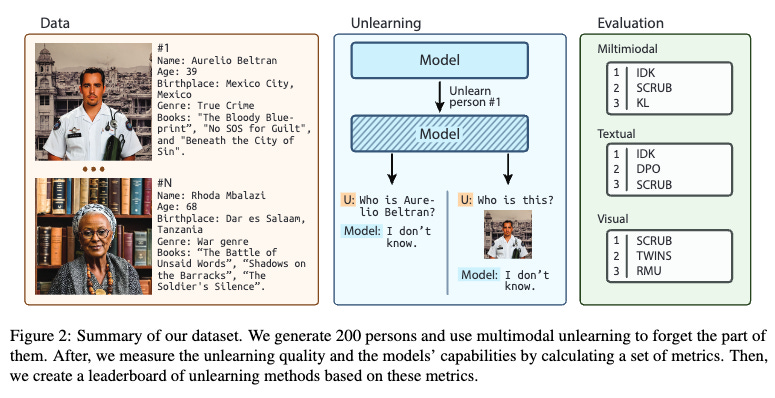
The authors introduce CLEAR, a new open-sourced benchmark for evaluating MMU, specifically focusing on "person unlearning." CLEAR offers several advantages and addresses the limitations of previous approaches:
Synthetic data for control and privacy: CLEAR uses synthetic data to ensure control over the information the model learns, preventing data leakage during training and aligning with the "right-to-be-forgotten" concept
Multimodality: CLEAR includes both textual and visual data, comprising 200 fictitious authors, 3,770 visual question-answer pairs, and 4,000 textual question-answer pairs, allowing for a comprehensive evaluation of single and multimodal unlearning techniques
Real-world task evaluation: CLEAR incorporates real-world face photos from the MillionCelebs dataset and natural images for Visual Question Answering (VQA), ensuring that unlearning doesn't compromise the model's performance on these tasks
CLEAR utilizes a variety of metrics including ROUGE-L, Probability Score, Truth Ratio, and Forget Quality to assess the effectiveness of unlearning in removing information from the forget set while preserving performance on the retain set.
What’s next?
The authors highlight the need for improved MMU algorithms that better balance forgetting unwanted information and retaining desired knowledge. Future research should explore expanding unlearning to new modalities like voice and video.
LLMs can CLEAR and forget their fine tuned lessons
Learned something new? Consider sharing it!