
Duo Attention Heads allow 3.3M wins!
Llama-3-8B model can handle up to 3.3 million contextual tokens
Paper: DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads (20 Pages)
Github: https://github.com/mit-han-lab/duo-attention
Researchers from MIT, Tsinghua University, SJTU, University of Edinburgh and NVIDIA are interested in long-context inference problem.
Hmm..What’s the background?
Large language models (LLMs) are revolutionizing AI, powering tasks like multi-round dialogues, long document summarization, and visual/video understanding. These applications frequently require processing vast numbers of tokens, creating the long-context inference problem.
Existing solutions to the long-context inference problem are inadequate in the following ways:
Linear Attention methods are efficient but underperform in long-context scenarios
Approximate attention methods (H2O, StreamingLLM, TOVA, FastGen) often sacrifice accuracy and aren't compatible with key optimizations like GQA
System-level optimizations like FlashAttention and PagedAttention are effective but don't reduce KV cache size and still require significant computation for extended contexts

Ok, So what is proposed in the research paper?
DuoAttention addresses these limitations by recognizing the dichotomy between Retrieval Heads and Streaming Heads within LLMs, in the following way:
Retrieval Heads are crucial for processing long contexts, capturing contextually relevant tokens, and require full attention across all tokens
Streaming Heads primarily focus on recent tokens and attention sinks and can operate effectively with a reduced KV cache
DuoAttention seamlessly integrates with techniques like GQA and quantization, further boosting efficiency. Combined with 8-bit weight 4-bit KV cache quantization, it enables a Llama-3-8B model to handle up to 3.3 million contextual tokens on a single A100 GPU – a 6.4× capacity increase compared to standard full attention FP16 deployments.
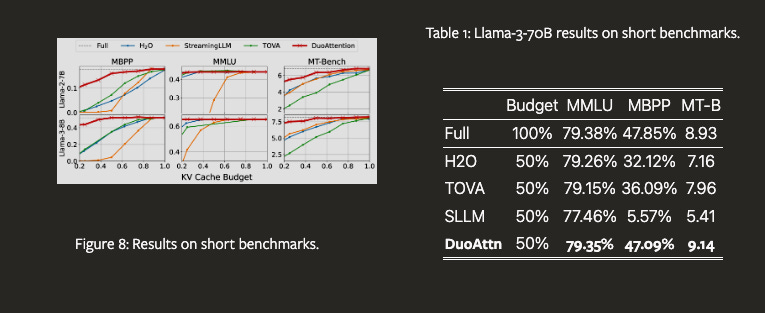
Extensive evaluations on long-context (Needle-in-a-Haystack, LongBench) and short-context (MMLU, MBPP, MT-Bench) benchmarks demonstrate DuoAttention maintains model performance while significantly improving efficiency.
What’s next?
DuoAttention's ability to handle ultra-long contexts opens doors for novel applications in areas like multi-document summarization, conversational AI with extensive memory, and knowledge retrieval.
Llama-3-8B model can handle up to 3.3 million contextual tokens
Learned something new? Consider sharing it!