
DeepMind releases Distributed Low-Communication LLM Training

DiLoCo does not seem like loco idea
Paper: DiLoCo: Distributed Low-Communication Training of Language Models
Researchers from DeepMind are interested in low-communication learning at scale.
Hmm..What’s the background?
Traditional LLM training requires large number of tightly interconnected accelerators, complex management of gradient and parameter exchanges at each optimization step, potential training halts due to device failures, and inefficient utilization of heterogeneous devices. Based on Federated Learning, where multiple workers, each with their own data partition, the researchers train model replicas locally and periodically synchronize their gradients.

So what is proposed in the research paper?
Here are the main insights:
DiLoCo combines a large number of inner optimization steps using AdamW as the inner optimizer with an outer optimization step using Nesterov momentum to aggregate updates from distributed workers
DiLoCo achieves significantly reduced communication compared to fully synchronous training
DiLoCo is robust to computational resources becoming unavailable or becoming available during training
The work demonstrates that pruning outer gradients using sign-based pruning can further reduce communication costs with negligible loss in performan
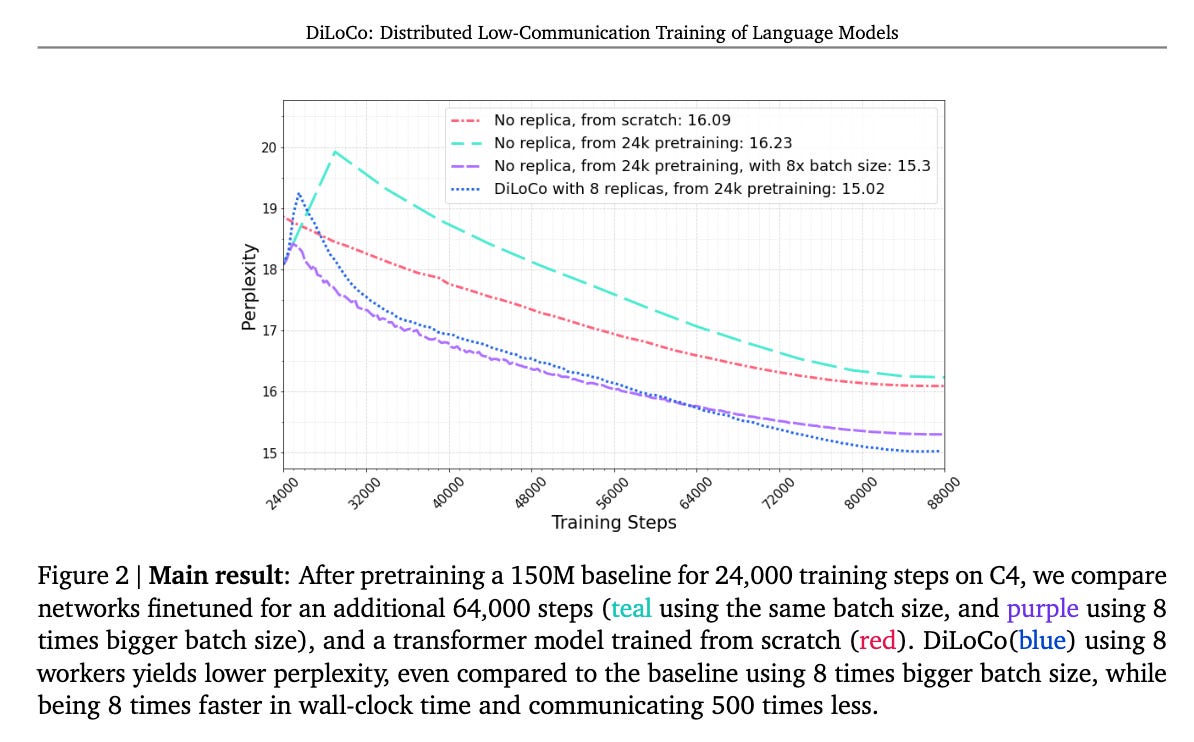
Source: Paper

What’s next?
Future work could explore the effectiveness of DiLoCo on different machine learning tasks beyond language modeling (e.g., vision) and other neural network architectures beyond transformers (e.g., CNNs). Further research can enhance DiLoCo's ability to effectively leverage compute resources beyond 8 workers, as diminishing returns were observed.
DiLoCo does not seem like loco idea
Learned something new? Consider sharing it!