
CPU Renaissance 🚀

So essentially,
We can run LLMs on edge CPU faster than GPU!
Paper:
T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge (14 Pages)
Github:
https://github.com/microsoft/T-MAC
Researchers from USTC, UCAS and Microsoft Research are interested in enhancing the efficiency of deploying Large Language Models (LLMs) on edge devices, particularly the ones with limited resources.
Hmm..What’s the background?
LLMs offer benefits such as reduced response latencies, enhanced user privacy, and operational reliability. However, they also present challenges such as substantial memory requirements, high computational and memory bandwidth demands, and power or energy efficiency concerns.
To address these challenges, the paper proposes T-MAC, an innovative lookup table (LUT)-based method designed for efficient low-bit LLM inference on CPUs.

Ok, So what is proposed in the research paper?
The core of T-MAC lies in its innovative use of lookup tables (LUTs) to accelerate the computationally intensive matrix multiplications inherent in LLM inference. This approach, based on bit-wise calculations, allows for direct support of mixed-precision operations, a crucial aspect of low-bit LLM deployment, where low-precision weights are combined with higher-precision activations.
It uses a LUT-centric data layout with axis reordering and tiling to ensure LUT residence in the fastest on-chip memory and enable parallel lookup. Furthermore, it reduces LUT storage size through table quantization and mirror consolidation, which exploit symmetrical properties of table values and apply quantization techniques.
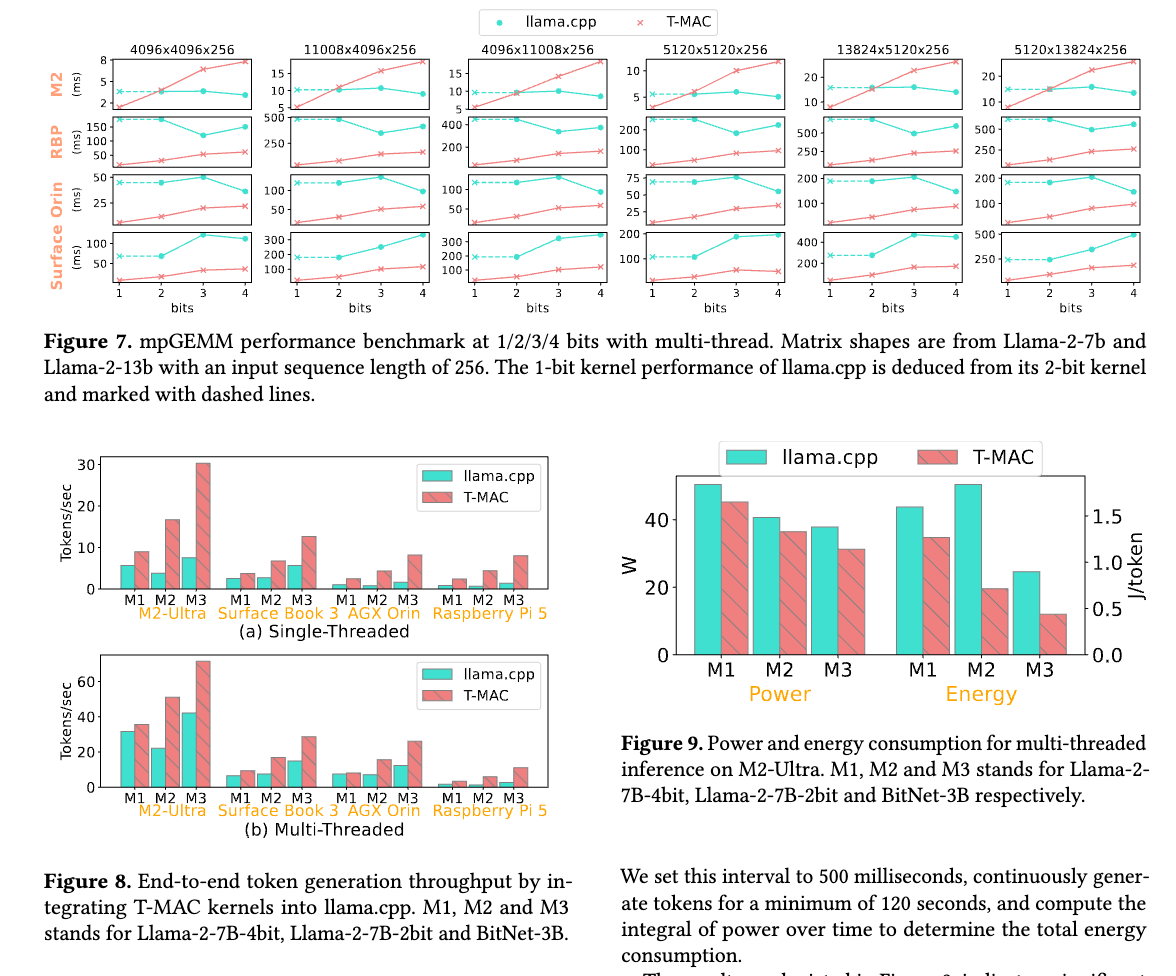
Evaluations of T-MAC on various edge devices demonstrate significant improvements in throughput and energy efficiency compared to traditional methods, paving the way for more responsive and power-efficient on-device AI applications.
What’s next?
While the researchers do not elaborate on specific hardware designs or research plans, the concluding statement highlights the promising nature of exploring LUT-based hardware accelerators specifically designed for LLMs.
So essentially,
We can run LLMs on edge CPU faster than GPU!