
AudioPaLM: A Large Language Model That Can Speak and Listen
Is this model going to replace Siri and Alexa?

Paper: AudioPaLM: A Large Language Model That Can Speak and Listen [27 pages]
Researchers at Google are introducing a new multimodal language model called AudioPaLM. This model fuses text based (PaLM-2) and speech baed models (AudioLM) into a unified architecture that can perform wonderful speech tasks such as recognition and translation with ease.
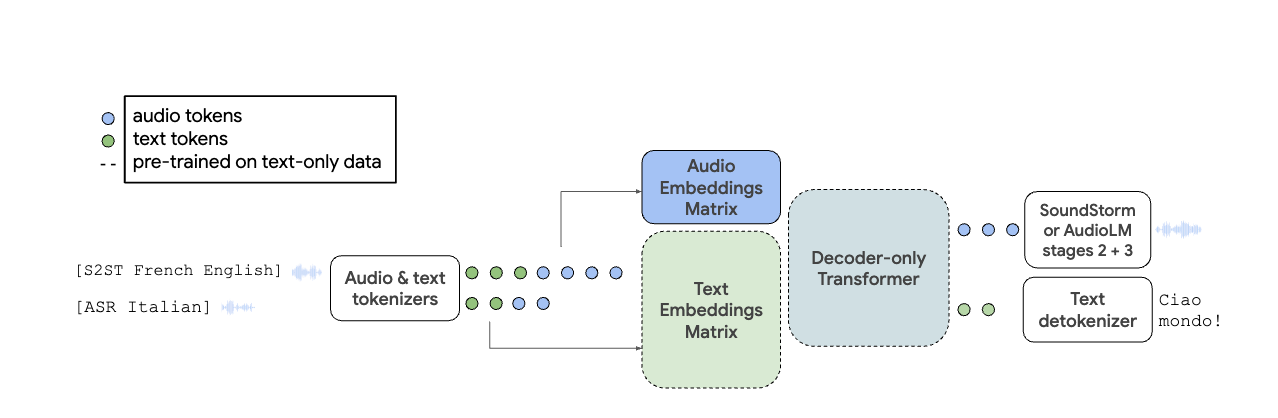
Here are some interesting discoveries in this paper:
They used a decoder only model which treats text and audio as tokenized inputs
Once the existing text decoders (PaLM-2) is modified, it can output raw audio
They used multiple datasets including YouTube ASR, WMT and Common Voice
They did a very thorough analysis of what factors create the best results includes dataset choice, model choice, training strategy and benchmarking quirks
Finally they were able to conclude that AudioPaLM demonstrates SOTA results on speech translation benchmarks and competitive performance on speech recognition tasks, as well as zero-shot speech-to-text translation. It can also benefit from features of audio language models, such as voice prompting, and can perform S2ST with voice transfer of a superior quality compared to existing baselines, as measured by both automatic metrics and human raters.

So essentially,
"Google has released an Audio + Text Large Language Model called AudioPaLM!"