
Apollo for Video Understanding
Apollo for Video Understanding Using LMMs
Paper: Apollo: An Exploration of Video Understanding in Large Multimodal Models
Researchers from Meta are interested in Apollo, a family of state-of-the-art Large Multimodal Models (LMMs) for video understanding, and provides a comprehensive study of various design choices that impact the performance of video-LMMs.
Hmm..What’s the background?
While image-language models have seen rapid advancements, video-LMMs have lagged behind, despite the rich, dynamic information that videos provide. Videos capture temporal and spatial features that static images cannot. However, video-LMMs face challenges such as higher computational demands and a more complex design space.
The study is motivated by the lack of systematic investigation into the impact of various design choices on video-LMM performance.
So what is proposed in the research paper?
Here are the main insights:
While image-language models have seen rapid advancements, video-LMMs have lagged behind, despite the rich, dynamic information that videos provide
Fundamental questions about video-LMM design remain unanswered, including how to sample videos, which vision encoders to use, and how to resample video tokens
The study introduces ApolloBench, a curated subset of existing benchmarks that significantly reduces evaluation time while improving assessment quality
Apollo-3B outperforms most existing 7B models, and Apollo-7B is state-of-the-art compared to other 7B LMMs.
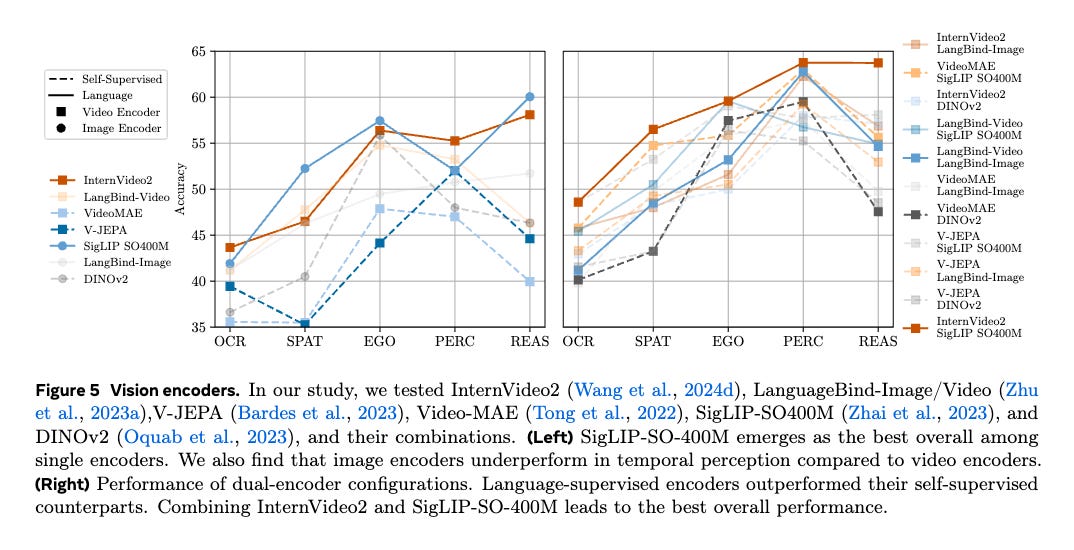
What’s next?
Researchers can explore separated architectures where images and videos are processed with different encoders could reveal performance benefits. They are interested in investigating training strategies for video and image encoders during supervised fine-tuning to understand their individual contributions to overall model performance.
Apollo for Video Understanding Using LMMs
Learned something new? Consider sharing it!