
AI fails badly in the real world
So essentially,
Multimodal Large Language Models have limited capabilities with real world scene dataset MME-RealWorld
Paper: MME-RealWorld: Could Your Multimodal LLM Challenge High-Resolution Real-World Scenarios that are Difficult for Humans? (34 Pages)
Researchers from multiple leading AI companies introduce MME-RealWorld as the largest fully human-annotated benchmark known to date of real world data.
Hmm..What’s the background?
Researchers have seen a significant increase in the development of Multimodal Large Language Models (MLLMs) that can perceive environmental situations through the integration of various multimodal sensory data. Several benchmarks have been created to assess the capabilities of MLLMs. There are issues with existing benchmarks such as the data scale, annotation quality, and task difficulty.
This research proposes a new benchmark called MME-RealWorld to address the shortcomings of the existing benchmarks.

Ok, So what is proposed in the research paper?
Here are the key features of paper:
The benchmark includes more than 29,429 question-answer pairs, over 13,366 high-resolution images, and 43 subtasks across 5 real-world scenarios
The images have an average resolution of 2,000 x 1,500 pixels
The five real-world scenarios included in the benchmark are: Optical Character Recognition (OCR) in the Wild, Remote Sensing, Diagram and Table, Autonomous Driving, and Monitoring
The benchmark also includes a Chinese version, called MME-RealWorld-CN. It consists of 5,917 question-answer pairs and 1,889 images focused on Chinese scenarios
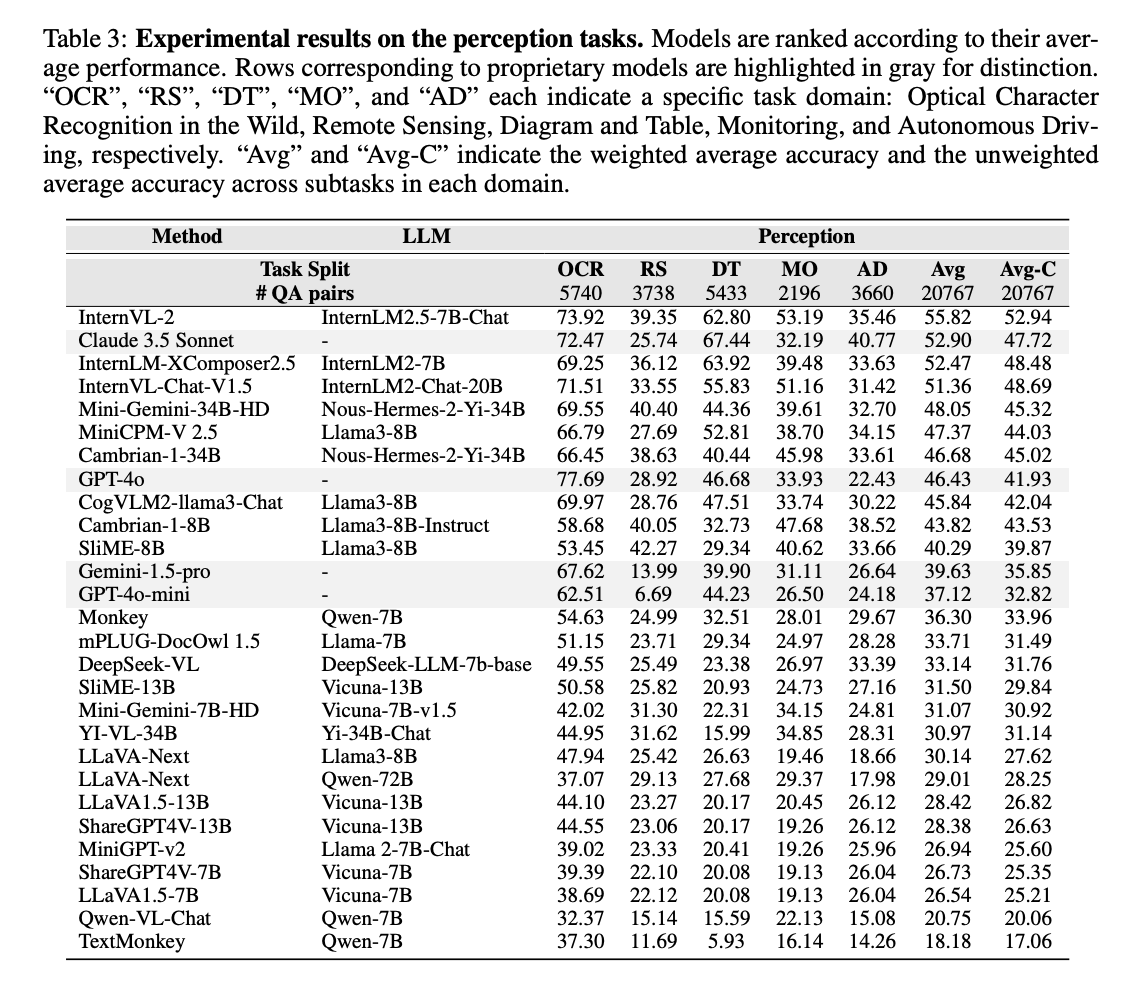
The InternVL-2 model achieved the best overall performance on both the perception and reasoning tasks, especially in the Chinese version of the benchmark. The GPT-4o model excelled in real-world OCR tasks, achieving 77% accuracy, but its performance was not as strong on other, more challenging tasks. The Claude 3.5 Sonnet model performed the best on the reasoning tasks across all the domains included in the benchmark.
What’s next?
The researchers propose exploring the following for future work
Effective techniques to handle high-resolution image
Improving models’ ability to understand dynamic information
Developing models with better image detail perception
So essentially,
Multimodal Large Language Models have limited capabilities with real world scene dataset MME-RealWorld
Learned something new? Consider sharing with your friends!