
AI can think while seeing and talking
So essentially,
Omni mini has real time speech reasoning!
Paper: Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming (10 Pages)
Researchers from Tsinghua University are interested in real-time speech interaction which is crucial for integrating language models into daily applications.
Hmm..What’s the background?
Audio Reasoning is complex and adding speech input and output modules makes models more complex. Directly training models for audio reasoning is difficult and often results in nonsensical outputs. The paper emphasizes a new approach with Mini-Omni, making it the first open-source model to achieve real-time speech-to-speech conversation.

Ok, So what is proposed in the research paper?
To address the observation that audio responses tend to be less sophisticated than text responses, the researchers employ batch processing. This involves running two parallel inferences: one for both text and audio responses, and one for text-only. The text output from the text-only inference is used to guide the audio generation of the first inference, thus enhancing the reasoning quality of the audio output.
Recognizing the shortcomings of existing datasets for training audio assistants, the authors introduce the VoiceAssistant-400K dataset. This dataset is specifically designed for speech model training and aims to reduce irrelevant outputs.
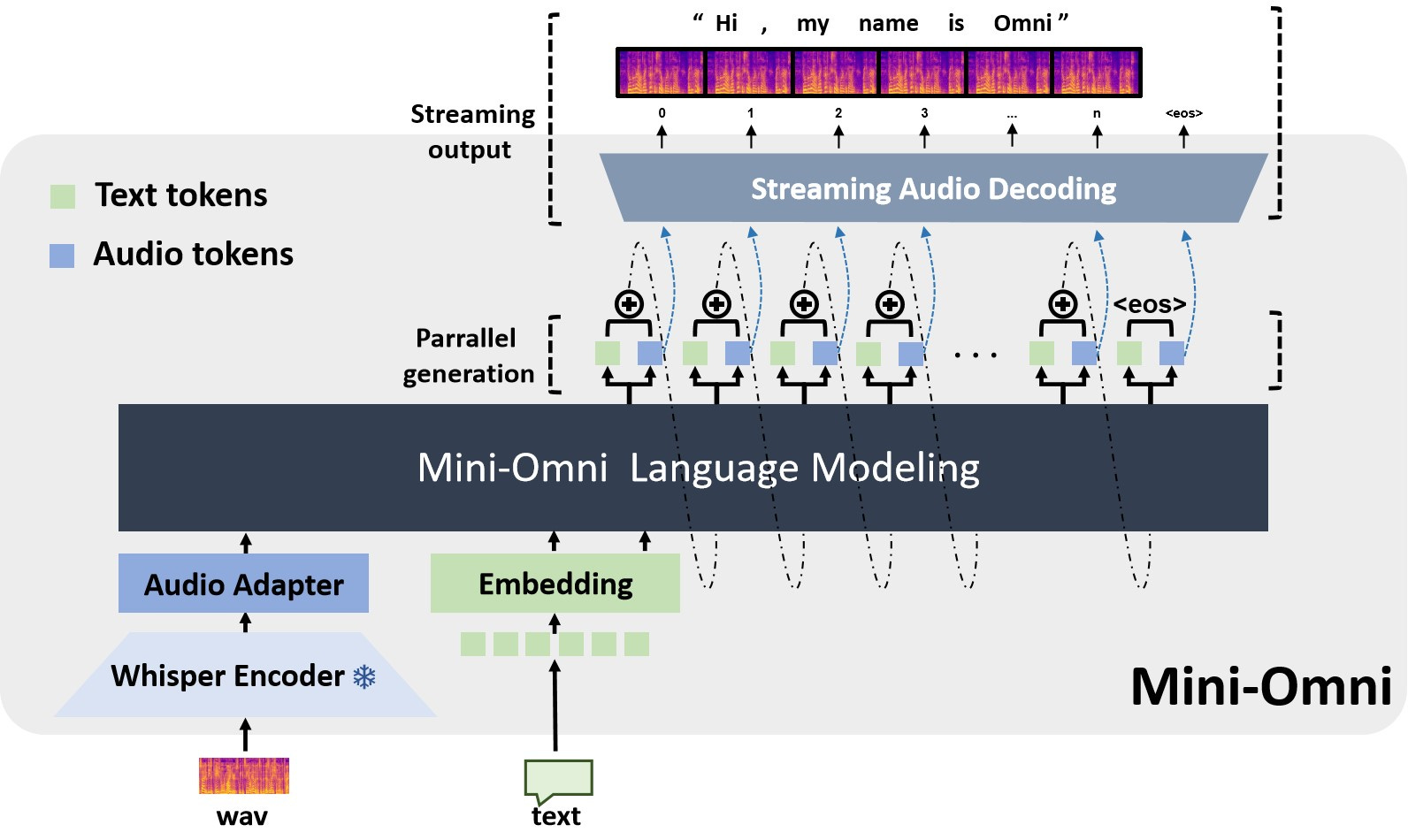
What’s next?
The researchers remark that these could directions for future work:
Improving Reasoning in Audio Modality: Although Mini-Omni introduces innovative techniques like batch parallel decoding to enhance audio reasoning, the paper notes that speech-based reasoning is still weaker compared to text-based reasoning
Expanding Model Capacity and Data: The authors hypothesize that the limitations in audio reasoning could stem from limited model capacity or insufficient audio data
So essentially,
Omni mini has real time speech reasoning!
Learned something new? Consider sharing with your friends!