

Molmo and PixMo
Open weight and open data VLMs are beating closed source models
Paper: Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models (8 Pages)
Website: https://molmo.allenai.org/
Researchers from Allen Institute for AI and University of Washington are interested in training their models on real data collected, annotated by humans and eliminating the reliance on synthetic data and closed source models.
Hmm..What’s the background?
Most advanced, state-of-the-art VLMs are primarily proprietary. This lack of access to model weights, training data, and code hinders scientific exploration and progress in the field.
While there are open-weight VLMs, they often rely on synthetic data generated by proprietary VLMs (like GPT-4V). This dependence on closed systems means that the open models are essentially "distillations" of proprietary technology, rather than truly independent models.

Ok, So what is proposed in the research paper?
The researchers propose and implement a novel approach to collecting high-quality image captions by leveraging speech-based descriptions from human annotators. This method encourages more comprehensive and detailed descriptions compared to traditional text-based annotation. The audio recordings of these descriptions serve as evidence that the data is genuinely human-generated and not derived from existing VLMs, aligning with the project's commitment to avoiding reliance on synthetic data.
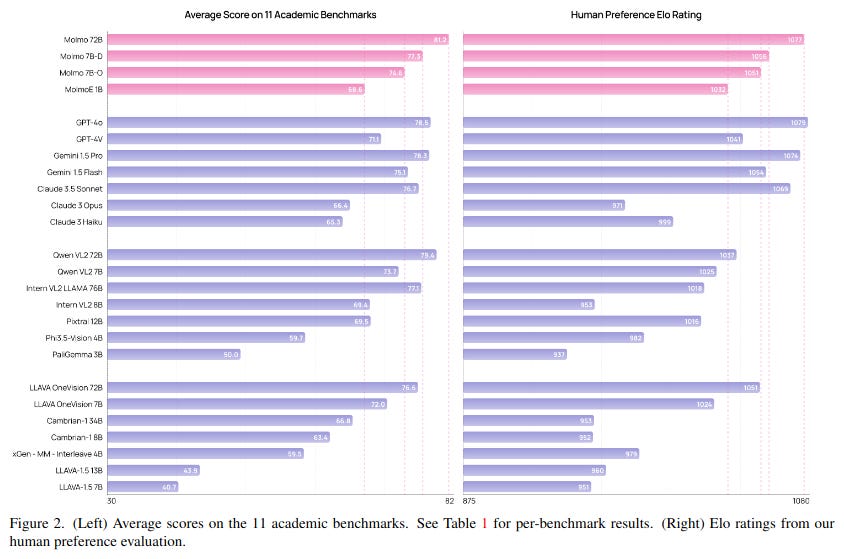
The sources emphasize that Molmo's best model, based on Qwen2 72B, exhibits exceptional performance, surpassing several state-of-the-art proprietary VLMs like Gemini 1.5 Pro and Flash, and Claude 3.5 Sonnet on both academic benchmarks and human evaluations.
The sources also showcase the efficiency of MolmoE-1B, which leverages the OLMoE-1B-7B mixture-of-experts LLM. Despite its smaller size, MolmoE-1B achieves performance comparable to GPT-4V on both academic benchmarks and human preference tests.
What’s next?
The researchers envision a future where VLMs, trained on datasets like PixMo-Points, empower agents (robots, web agents, etc.) to interact with their environments more effectively. These agents could utilize pointing to indicate navigation waypoints, objects for manipulation, or UI elements for interaction. This highlights the potential of Molmo's research to extend beyond traditional VLM capabilities into the realm of embodied AI and agent-environment interaction.
So essentially,
Open weight and open data VLMs are beating closed source models
Learned something new? Consider sharing it!